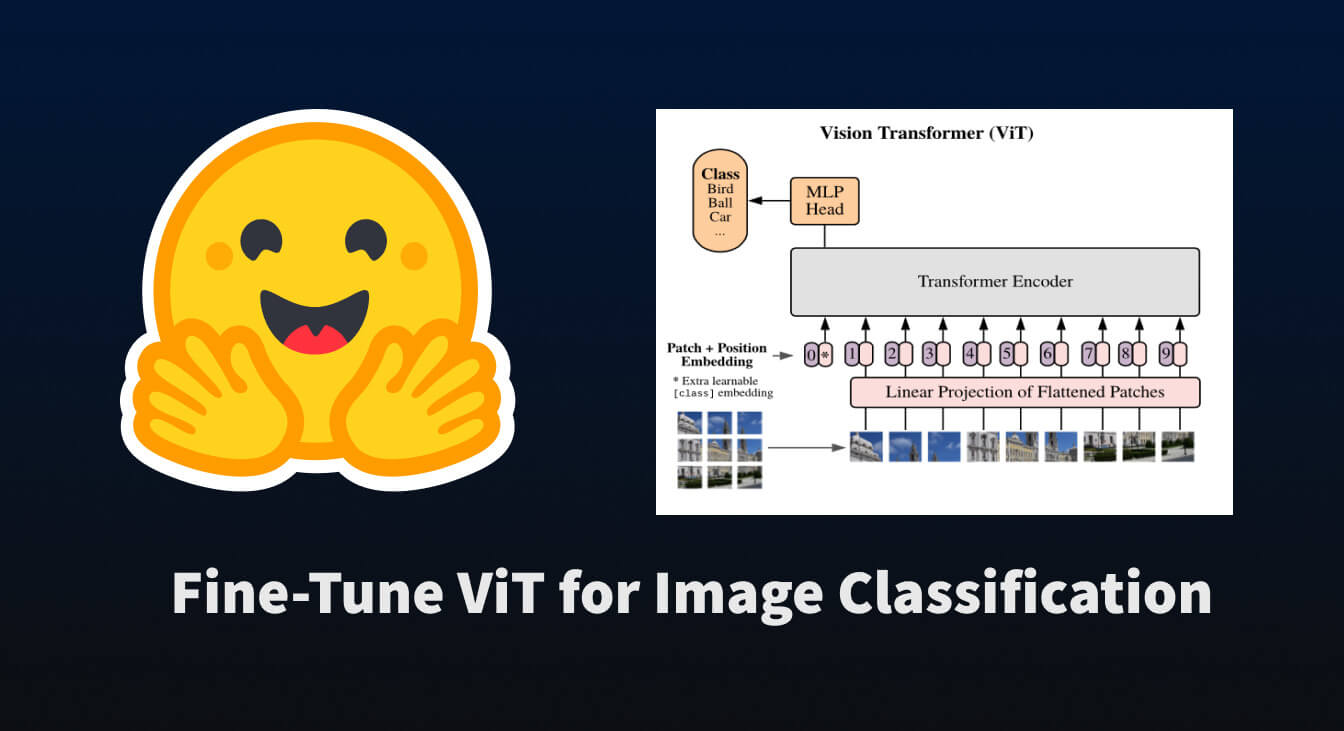
Hugging Face 发布了一份关于微调 Vision Transformer (ViT) 模型以进行图像分类任务的指南。该教程使用了 🤗 Transformers 库,演示了如何将预训练的 ViT 模型适配到特定数据集。这个过程允许开发者利用强大的预训练模型进行定制图像识别应用,而无需从头开始训练。 AI
排序理由 该条目描述了一个关于微调视觉 Transformer 模型的教程,属于研究和模型适配类别。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →