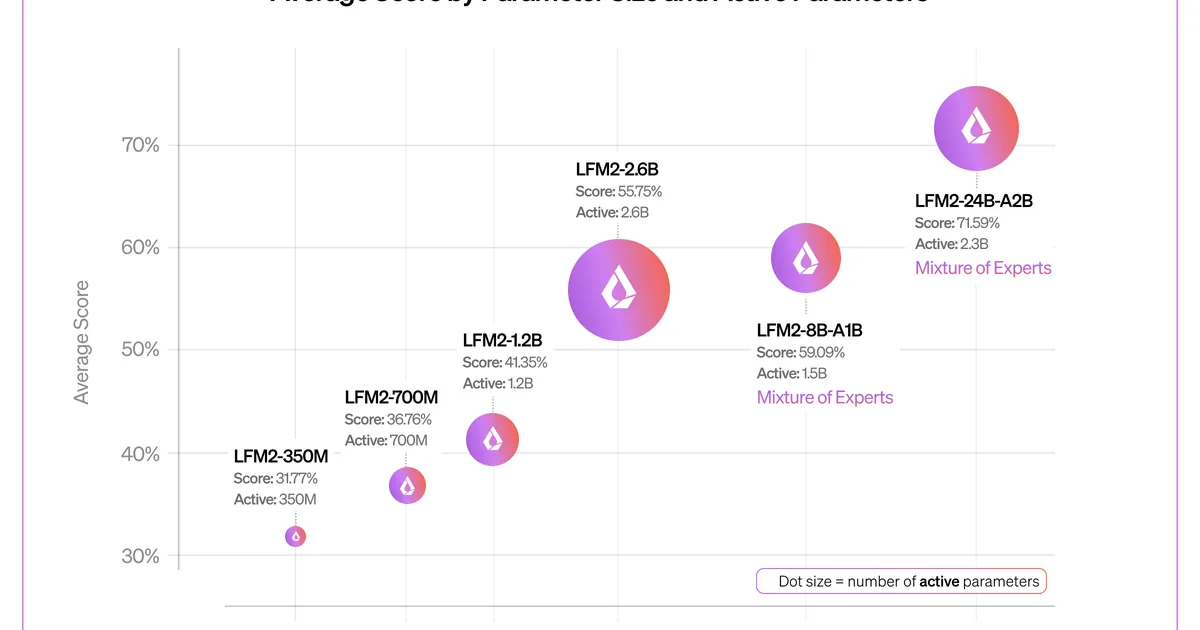
Liquid AI 发布了其 LFM2-24B-A2B 模型的早期检查点,这是一种稀疏专家混合(MoE)架构,总参数量为 240 亿,每个 token 激活参数量为 20 亿。该模型证明了 LFM2 架构能够有效地扩展到更大的规模,并且随着该系列的不断发展,在基准测试中观察到了持续的质量提升。LFM2-24B-A2B 设计为可容纳在 32GB RAM 中,旨在部署在云和边缘环境,包括消费级笔记本电脑和台式机。 AI
影响 提供了一款边缘可部署的 MoE 模型,该模型在参数数量和激活参数之间取得了平衡,实现了高效推理。
排序理由 发布了一款具有详细架构和基准测试信息的开放权重模型,但并非来自顶级前沿实验室。
在 Hacker News — AI stories ≥50 points 阅读 →
- gpt-oss-20b
- Hugging Face
- LFM2
- LFM2-24B-A2B
- llama.cpp
- Mixture of Experts
- Qwen3-30B-A3B-Instruct-2507
- Liquid AI
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →