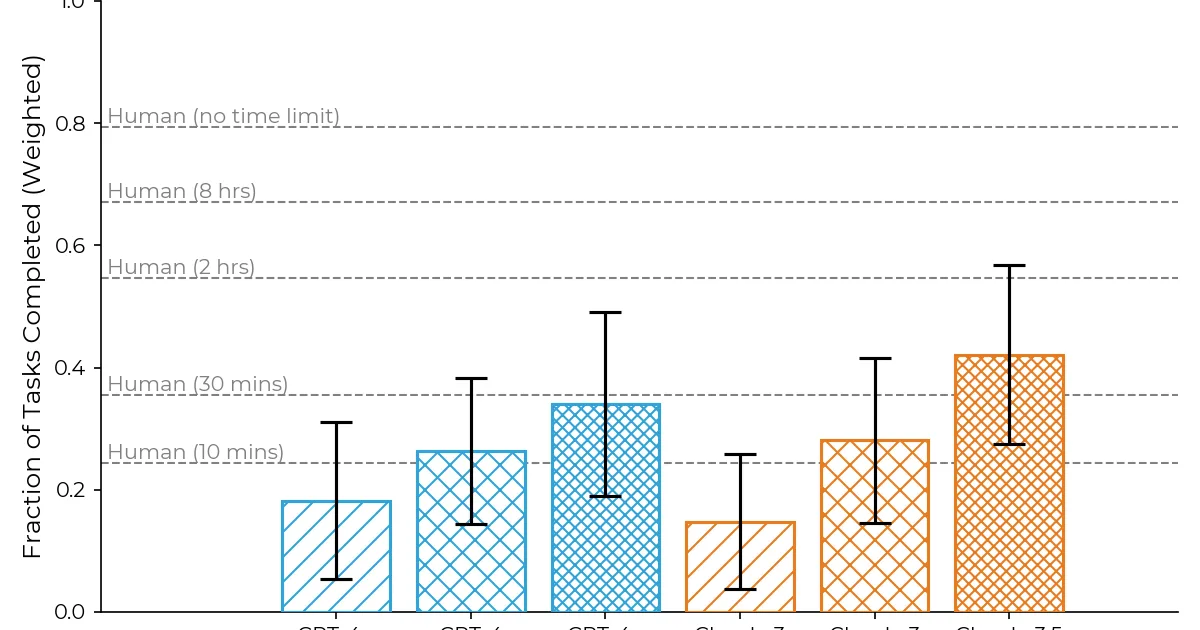
METR 发布了对 GPT-4o 在 77 项任务上的自主能力进行评估的初步结果。该模型展现了系统性探索等令人印象深刻的技能,但也表现出突然放弃或得出不支持的结论等故障模式。虽然在某些任务上的表现与人类基线相当,但 GPT-4o 被发现比 Claude 3 Sonnet 和 GPT-4 Turbo 更强大,但略逊于 Claude 3.5 Sonnet。 AI
影响 提供了对 GPT-4o 自主代理性能和故障模式的见解,为未来的模型开发和评估策略提供信息。
排序理由 这是一篇评估现有模型能力的学术论文。
在 METR (Model Evaluation & Threat Research) 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →