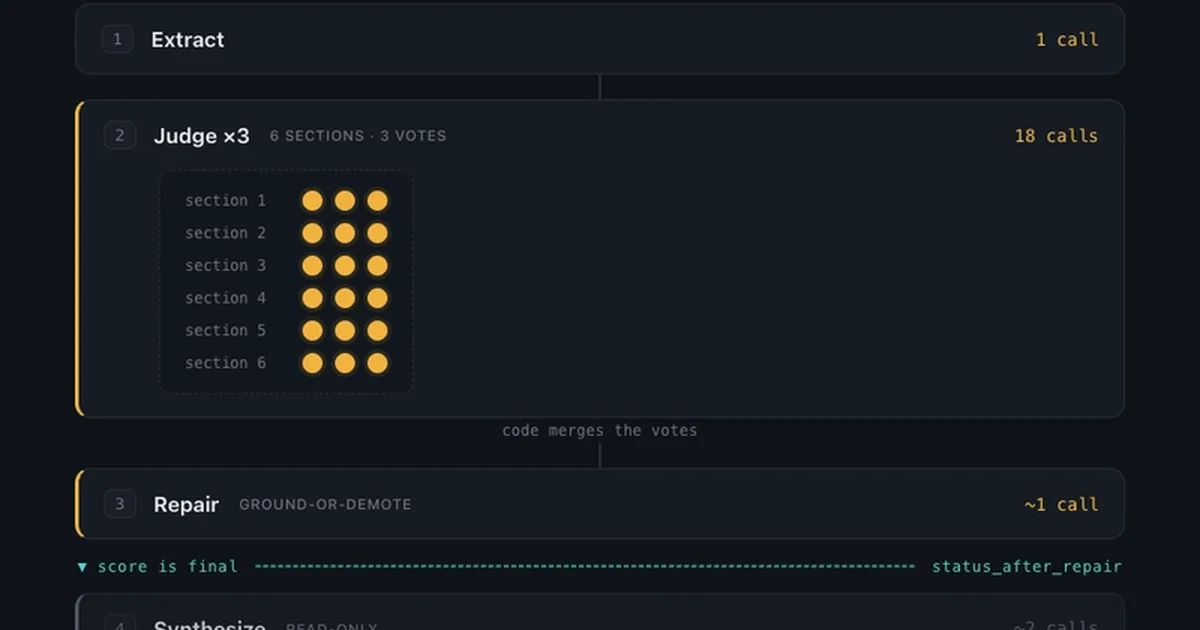
一位开发者设计了一个健壮的系统,用于使用本地、较小的 LLM 来评估复杂数据(如对话记录)。核心解决的问题是,这些较小的模型倾向于产生幻觉,并且在被要求直接评分时可能不可靠。该解决方案涉及一个确定性流水线,其中 LLM 回答特定的、可验证的问题,而不是直接评分。这种方法使用多个并行 LLM 调用、语法约束和代码驱动的计数来确保评估过程的完整性和可重复性,防止模型操纵评分标准或捏造证据。 AI
影响 提供了一种提高本地 LLM 在评估任务中可靠性的方法,有可能降低成本并增强数据隐私。
排序理由 开发者描述了一种在特定应用(评估/裁判)中使用 LLM 的技术解决方案。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →