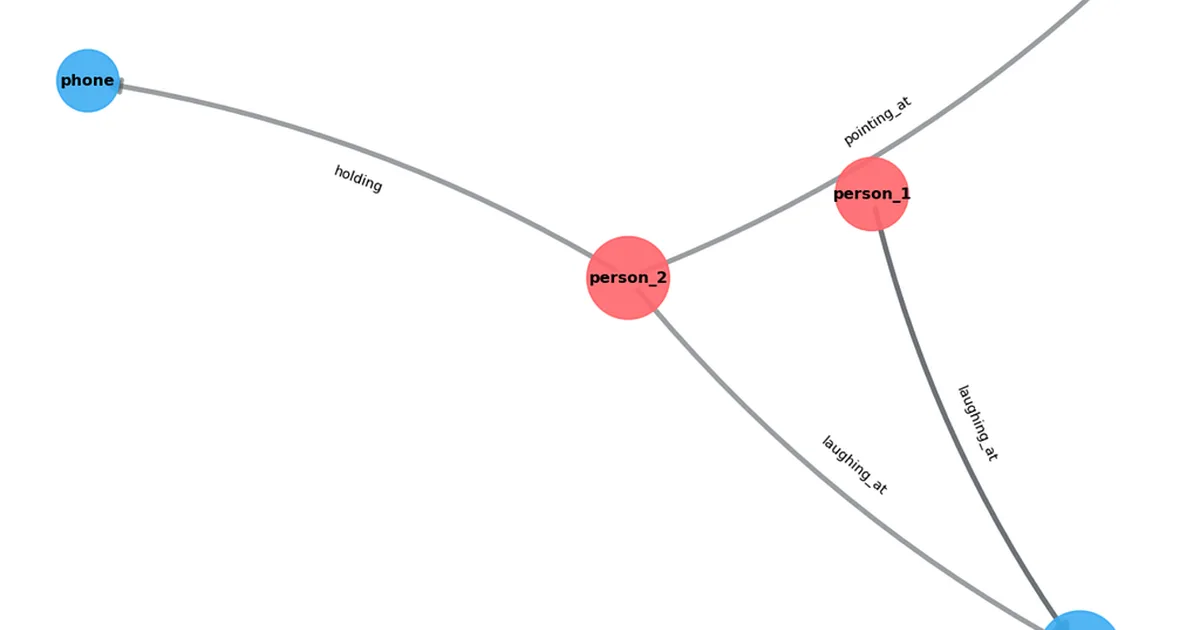
一种新的视频场景图生成(SGG)方法利用视觉语言模型(VLMs)来创建视频内容的结构化、机器可读的描述。与依赖固定词汇的传统 SGG 方法不同,这种方法使用 Qwen2.5-VL 等开放词汇 VLMs 直接从视觉和语言线索生成描述。该过程包括从视频中选择关键帧,然后使用 VLM 识别对象、人物及其关系,形成一个可编程分析的图。 AI
影响 通过生成结构化的开放词汇场景图,实现对视频内容的编程理解。
排序理由 该条目描述了一种使用 VLMs 进行视频场景图生成的新颖方法,包括实现细节和代码。[lever_c_demoted from research: ic=1 ai=1.0]
- AutoProcessor
- Kartikeya
- Medium
- NetworkX
- NumPy
- PyTorch
- Qwen2.5-VL
- Qwen2_5_VLForConditionalGeneration
- transformers
- Video Scene Graph Generation
- Vision--Language Models
- Visual Genome
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →