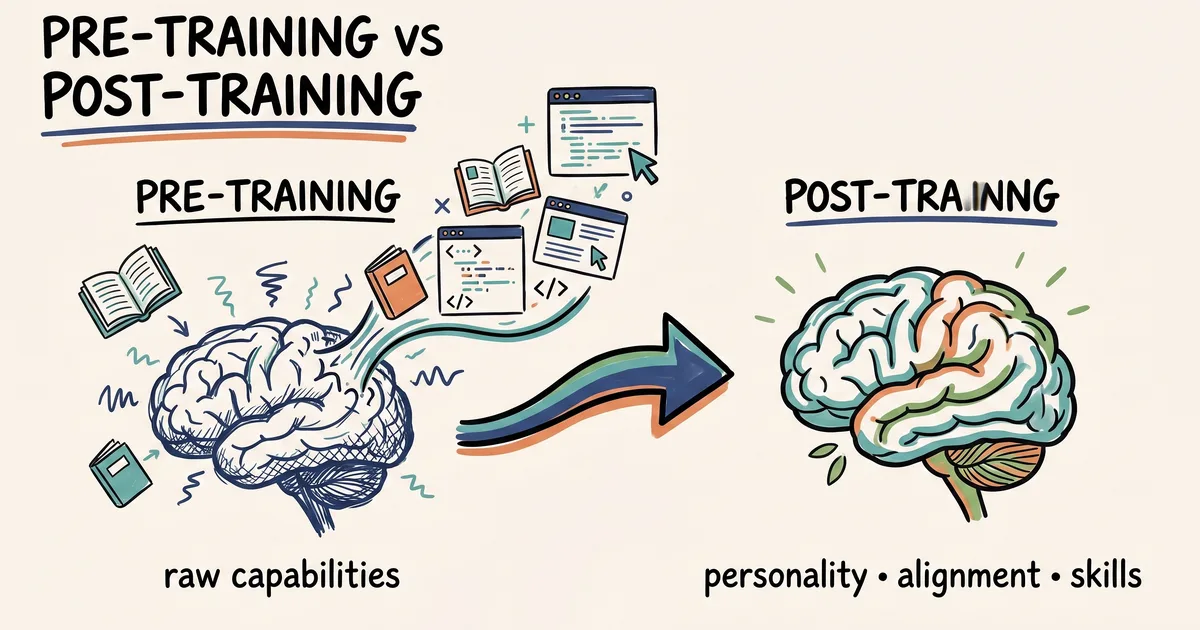
本文深入探讨了监督微调(SFT),这是大型语言模型的一种关键训练后技术。它解释了SFT如何塑造原始语言模型的行为,使其更符合期望的输出和功能。该文是探讨不同训练后方法系列的第一部分。 AI
影响 解释了使LLM行为与用户意图保持一致的核心技术。
排序理由 该项目是对机器学习技术的技术解释,符合研究类别。[lever_c_降级自研究:ic=1 ai=1.0]
在 Medium — fine-tuning tag 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →