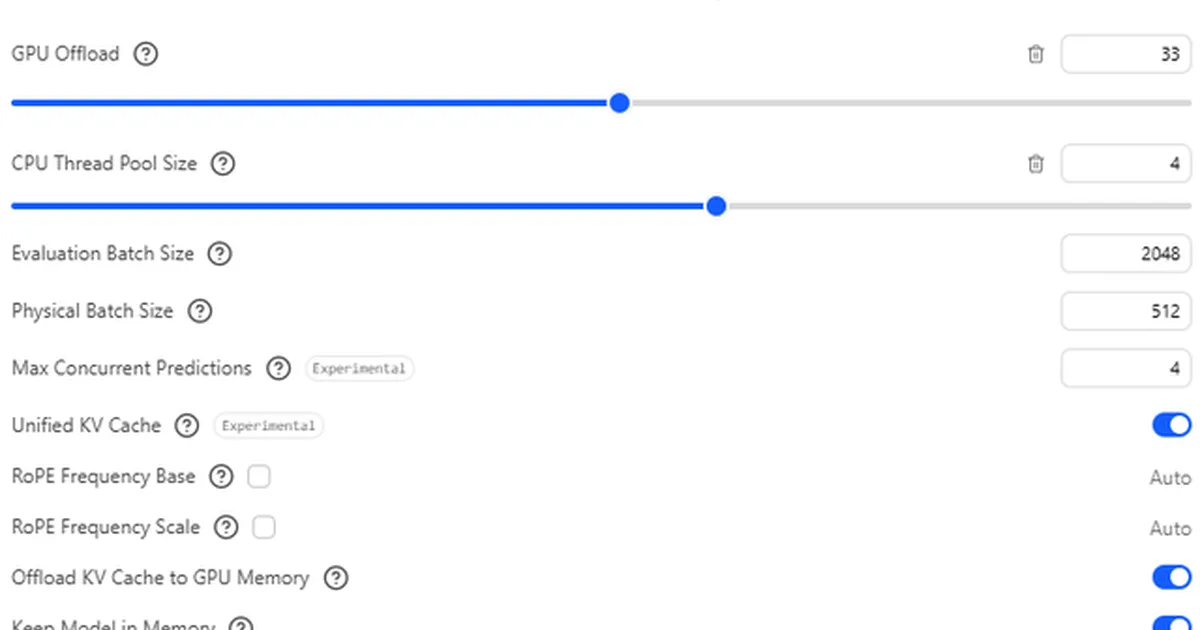
一位Reddit用户正在寻求优化其大型语言模型的RAM卸载,该用户系统拥有12GB VRAM和5200MHz双通道RAM。尽管拥有足够的RAM,用户仍面临推理速度慢和DRAM带宽低的问题,并质疑瓶颈是出在LM Studio、其CPU(Ryzen 5 7500F)还是其他系统配置上。他们已经尝试了各种设置,包括CPU线程数和GPU卸载百分比,以提高令牌生成速度。 AI
排序理由 用户在关于优化LLM推理硬件的细分subreddit上生成的内容,并非主要来源发布或重大行业事件。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →