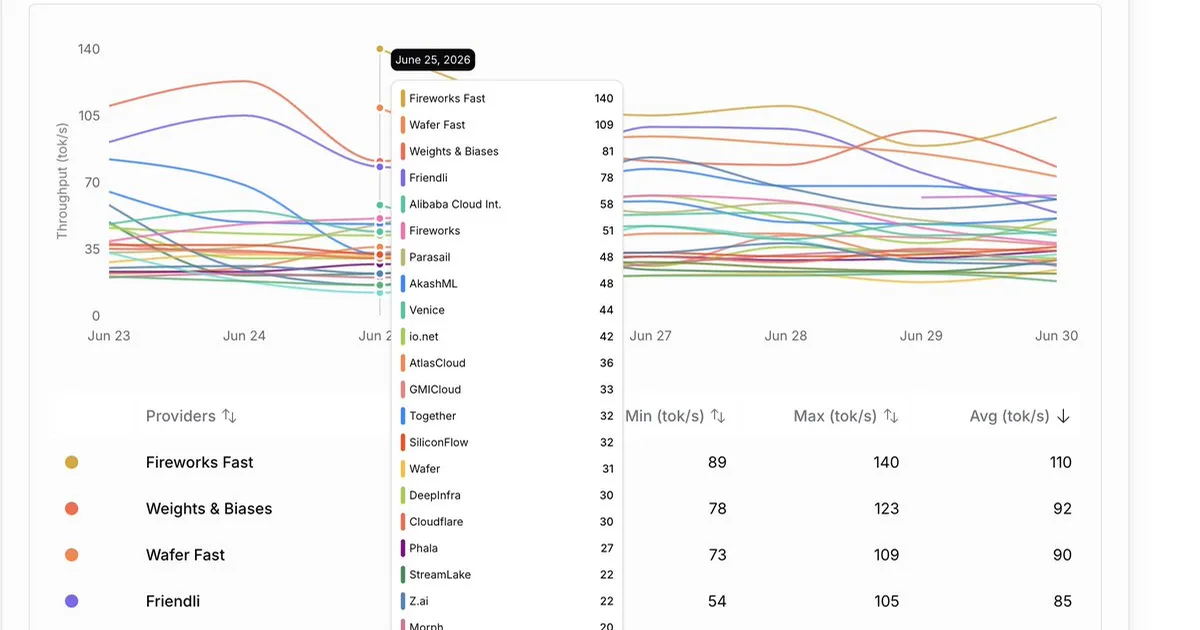
Fireworks AI发布了GLM 5.2模型的更快版本,名为GLM 5.2 Fast。新版本在保持标准GLM 5.2相同质量的同时,实现了显著更高的推理速度,最高可达每秒140个token。该公司还强调了用于实现更高性能的定制部署选项,指出在Artificial Analysis上速度可达每秒446个token。 AI
影响 提高LLM的推理速度,可能降低成本并改善实时应用程序性能。
排序理由 前沿AI实验室的模型发布。[lever_c_demoted from frontier_release: ic=2 ai=1.0]
在 X — Fireworks (inference infra) 阅读 →
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →