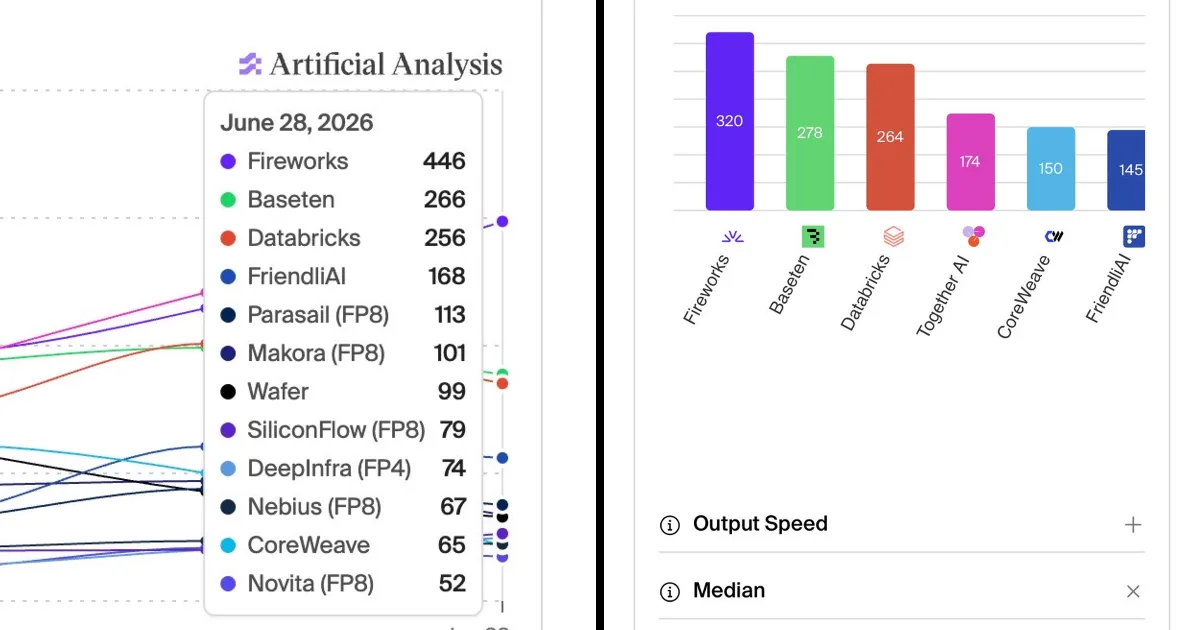
Fireworks AI 推出了 GLM 5.2 Fast,这是一款专为代理工作流设计的模型,其运行速度比标准版本快 2-3 倍。这种增强的速度对于处理大上下文、编写计划和使用工具的代理至关重要,使其更加实用且具成本效益。该模型支持 100 万个 token 的上下文窗口,并具有优化的提示缓存功能,为重复使用的上下文提供显著折扣,这是代理操作中的主要成本因素。GLM 5.2 Fast 采用了一种特殊的架构,结合了混合专家模型 (MoE) 和 DeepSeek 稀疏注意力与 IndexShare,从而通过将注意力集中在输入的最相关部分来高效处理长上下文。 AI
影响 通过显著提高长上下文任务的处理速度和成本效益,加速了代理工作流。
排序理由 来自前沿实验室 (Fireworks AI) 的模型发布,包含新的版本名称和性能声明。[lever_c_demoted from frontier_release: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →