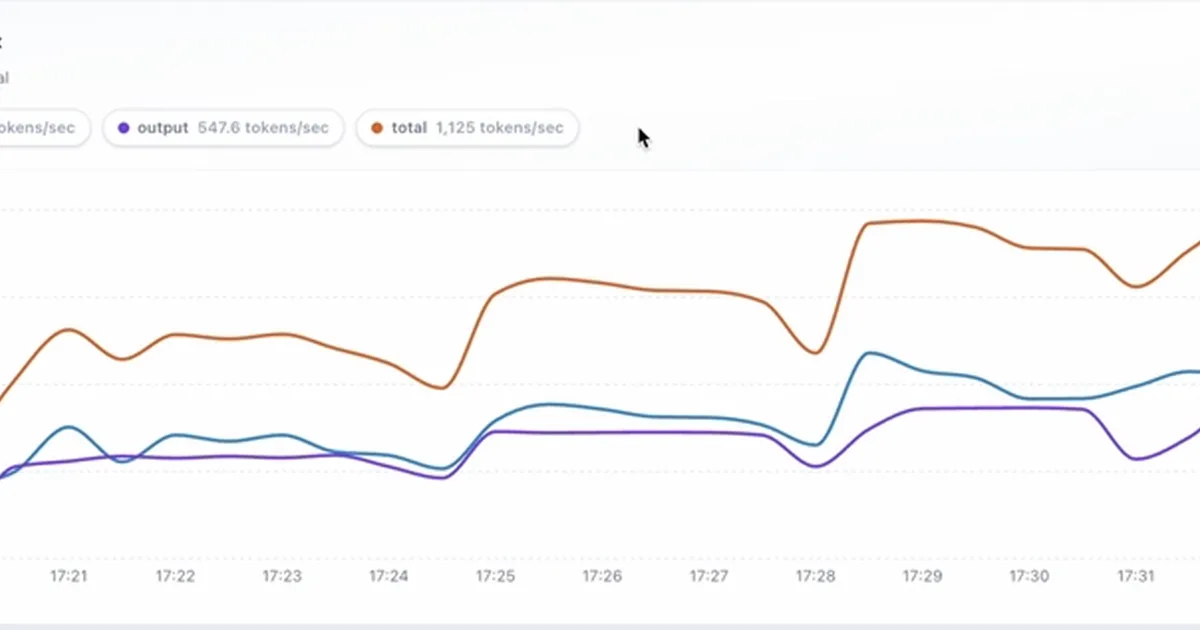
一篇技术博客文章详细介绍了 Gemma-4 31B 模型在单个 RTX 6000 PRO Blackwell GPU 上使用 vLLM 运行时所达到的性能。该配置在大约 24 个并发请求下实现了约 1,168 tokens/sec 的峰值吞吐量,显示出显著的容量和余量。虽然中位数首次 token 时间保持在约 0.7 秒的快速水平,但在重负载下,尾部延迟(p99)增加到约 19 秒,突显了这是扩展的关键指标。 AI
影响 展示了特定 LLM 和硬件配置在生产工作负载下的推理能力。
排序理由 博客文章详细介绍了 LLM 在特定硬件上的性能基准测试。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →