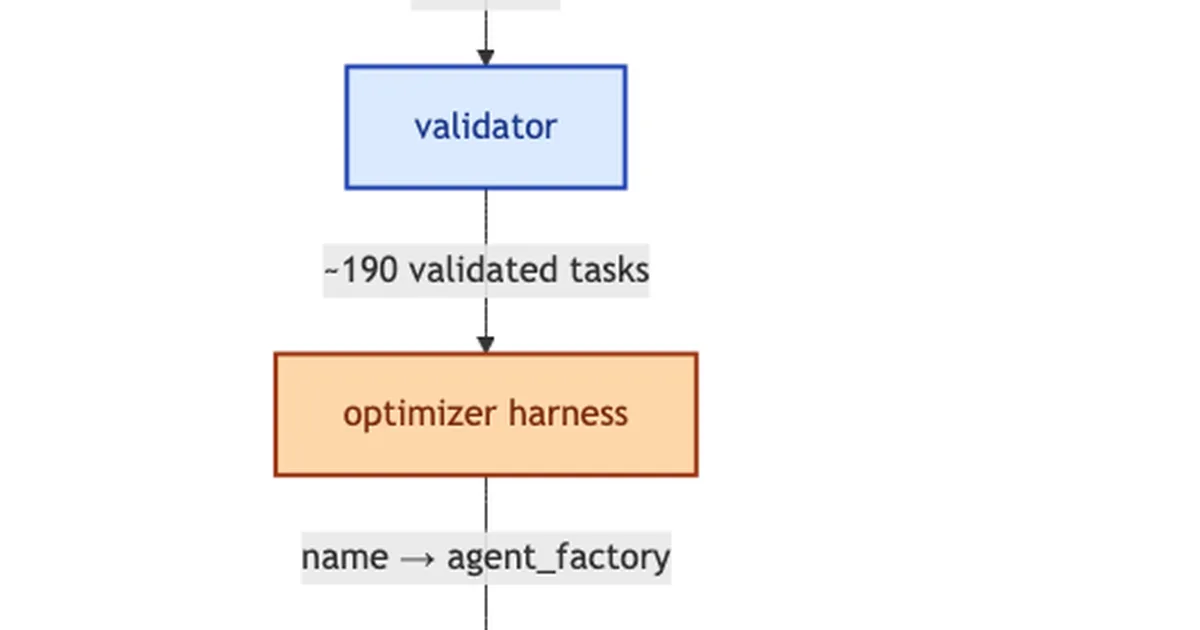
开发了一个新的基准测试,以研究大型语言模型(LLMs)的提示优化技术是否会削弱它们对抗恶意攻击(特别是提示注入)的鲁棒性。初步研究结果表明,虽然提示优化可以提高在干净数据集上的准确性,但可能会导致对抗提示注入攻击的安全性下降。该基准测试旨在弥合提示优化和提示注入研究社区之间的差距,这两个社区历史上一直独立运作。 AI
影响 这项研究可以为开发人员在使用优化工具时,在提示准确性和安全性之间的权衡提供信息。
排序理由 该条目描述了一个新的基准测试及其与大型语言模型提示优化和对抗性鲁棒性相关的初步研究结果,以研究帖子形式呈现。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →