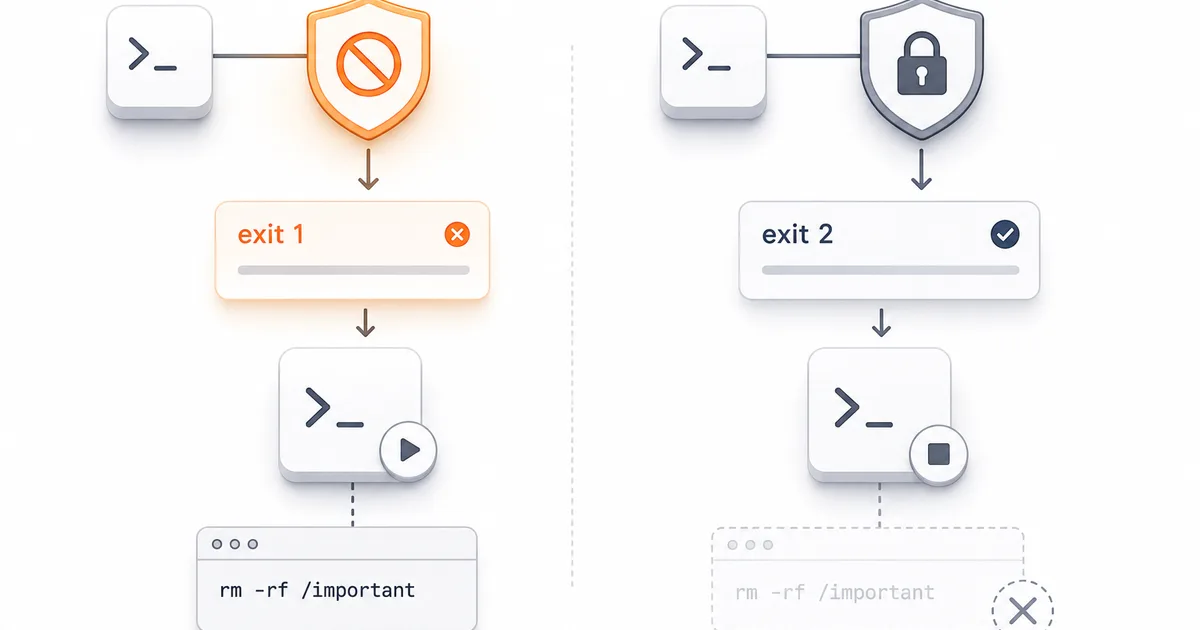
Anthropic 开发的 AI 模型 Claude Code 中已发现一个安全漏洞。该问题在于模型如何处理退出命令,特别是“exit 1”。虽然用户可能期望“exit 1”会停止危险命令,但 Claude Code 仅将“exit 2”识别为执行此目的。这一疏忽意味着潜在的有害命令可能会在没有中断的情况下执行,从而构成安全风险。 AI
影响 此漏洞可能使用户面临 Claude Code 中意外执行危险命令的风险。
排序理由 识别出 AI 产品中的特定安全缺陷。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →