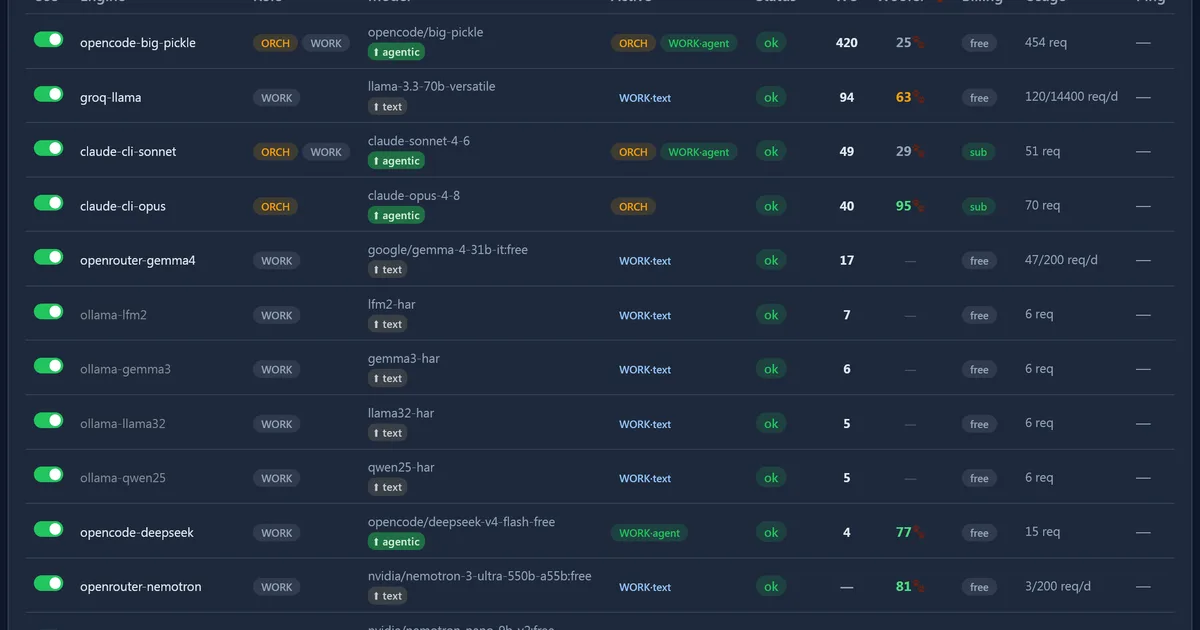
一位用户开发了一个“WOOFER”指标,使用“Probe_prompt”来评估大型语言模型 (LLM) 的性能。该指标产生了一些令人惊讶的结果,一些模型的得分出人意料地低,例如 # bigpickle 得分为 25,而一组小型模型(LFM2、Gemma3 (2B)、Llama32 和 Quen25)的共识得分仅为 18。值得注意的是,# Claude # Opus 评估自己的回应是天才,而较新的 # Nvidia 模型 nematron 根据 WOOFER 分数表现良好。 AI
影响 引入了一种新颖但非正式的评估 LLM 能力的方法,可能会影响用户评估和比较模型的方式。
排序理由 该条目描述了用户个人开发和测试 LLM 新评估指标的过程,而不是正式发布或研究论文。
在 Mastodon — fosstodon.org 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →