English(EN)@ashVaswani @NoamShazeer @YesThisIsLion @metaai @MistralAI @tri_dao The long-context demands of agentic AI accelerated attention research aimed at overcoming th
开源AI中Transformer注意力机制的演进
作者PulseAugur 编辑部·[8 个来源]·
自诞生以来,Transformer架构的注意力机制经历了显著的演进,众多创新为更高效、更强大的大型语言模型做出了贡献。FlashAttention、多查询注意力(MQA)、分组查询注意力(GQA)和滑动窗口注意力(SWA)等创新极大地降低了内存需求并提高了推理性能。最新的进展,包括门控Delta网络(GDNs)等线性注意力变体和原生稀疏注意力(DSA)等稀疏注意力方法,正在进一步拓展边界,许多开源模型都采用了这些技术。
AI
@ashVaswani @NoamShazeer @YesThisIsLion @metaai @MistralAI @tri_dao @SonglinYang4 Around the same time, the vLLM inference engine and its underlying Paged Attention took the open-source community by storm. Started by @woosuk_k, the @vllm_project has become one of the most widely …
@ashVaswani @NoamShazeer @YesThisIsLion @metaai @MistralAI @tri_dao @SonglinYang4 As ChatGPT exploded in popularity, research on LLM serving became highly active. Efficient LLM serving remained a major challenge until the invention of KV cache-managing Attention methods, such as …
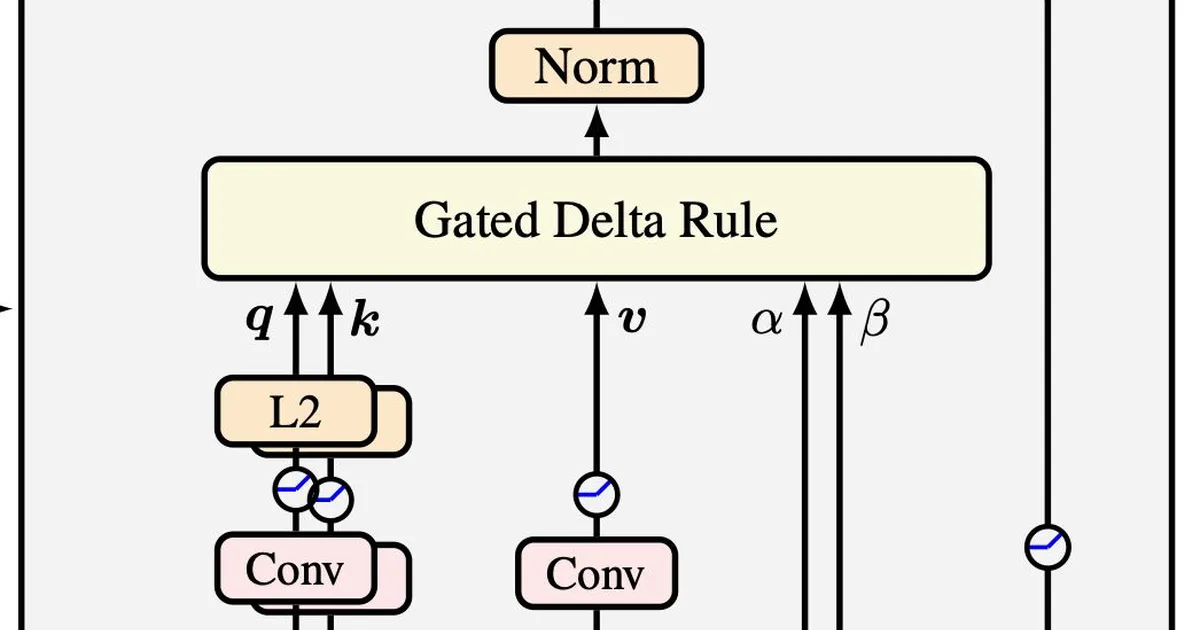
@ashVaswani @NoamShazeer @YesThisIsLion @metaai @MistralAI @tri_dao The long-context demands of agentic AI accelerated attention research aimed at overcoming the context wall. Over the past year, linear attention has become mainstream, most notably with Gated Delta Networks (GDNs…
@ashVaswani @NoamShazeer @YesThisIsLion @metaai @MistralAI @tri_dao Innovation in attention mechanisms did not stop, even though MHA/GQA/SWA remain hard to beat. In 2024, DeepSeek-V3/R1 demonstrated near-frontier capabilities, proving the effectiveness of their in-house Multi-Hea…
@ashVaswani @NoamShazeer @YesThisIsLion @metaai @MistralAI One of the greatest leaps since MHA was FlashAttention by @tri_dao. FlashAttention dramatically reduced memory requirements for both the forward and backward passes of attention, unlocking major performance gains and enab…
@ashVaswani @NoamShazeer @YesThisIsLion The early variants of MHA include Multi-Query Attention (MQA), invented by Noam Shazeer, Grouped-Query Attention (GQA), invented by the @MetaAI LLaMA team, and Sliding Window Attention (SWA), popularized by @MistralAI. MQA, GQA, and SWA bui…
In contrast to the slow decline of the Transformers movie series in 2017, the Transformer architecture in NLP showed immense potential. It introduced Multi-Head Attention (MHA) and dramatically improved perplexity scores. We thank @ashVaswani, @NoamShazeer, @YesThisIsLion, and ht…
Transformer’s Attention mechanism has come a long way. We’d like to thank the researchers and the engineers in the open-source community for continuing to make high-performance AI accessible. Please celebrate with us by sharing this post, tagging more contributors, and sharing ht…