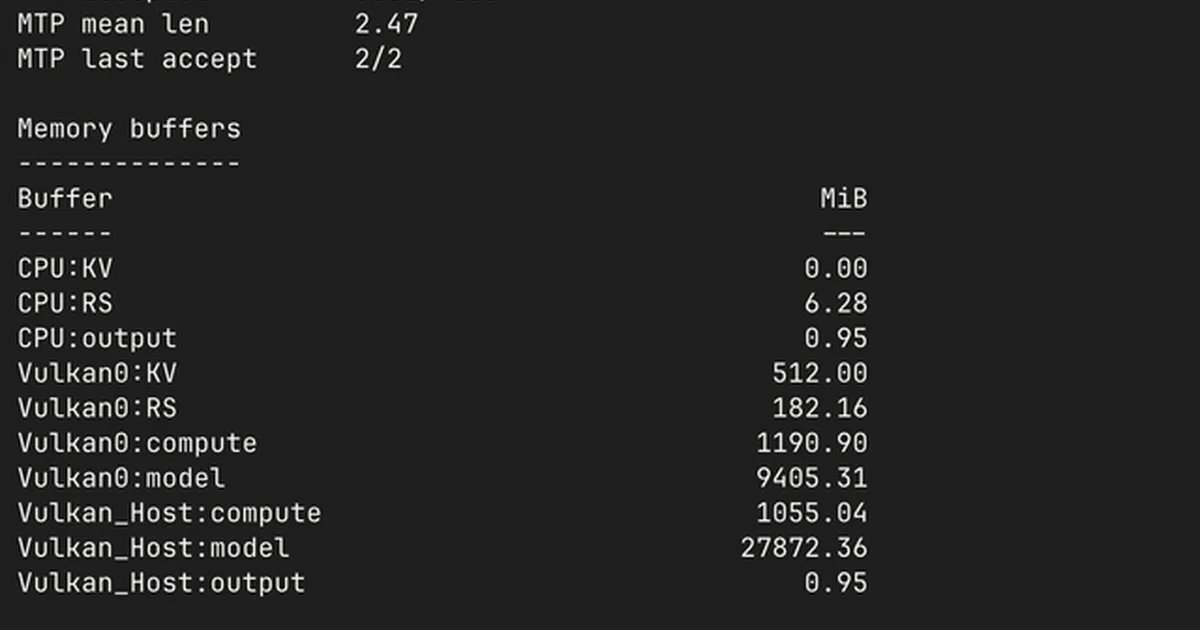
一位用户开发了一个脚本来监控和分析 llama.cpp 的内存使用情况,llama.cpp 是一个流行的用于大型语言模型的推理引擎。该脚本解析 llama.cpp 的详细输出,以提供缓冲区分配、内存需求以及每秒令牌数等性能指标的清晰摘要。目标是帮助使用普通硬件的用户更好地理解和预测各种模型(尤其是在使用不同量化级别时)的 VRAM 和 RAM 需求。 AI
影响 帮助用户优化在本地运行大型语言模型 (LLM) 的硬件使用。
排序理由 用户为特定软件工具开发的脚本。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →