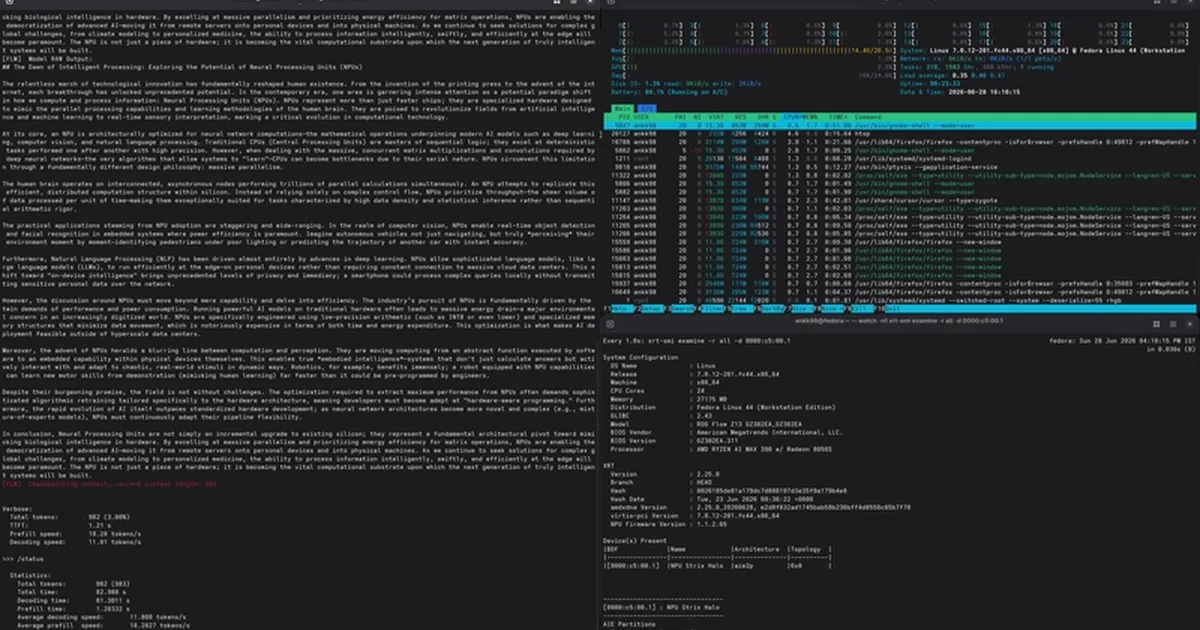
本指南详细介绍了如何在 Fedora Linux 上使用 FastFlowLM 在 AMD NPU 上运行大型语言模型 (LLM)。它概述了一个需要从源代码构建 XRT、NPU 插件和 FastFlowLM 的四层设置,因为 Fedora 没有预构建的软件包。主要挑战包括确保启用 IOMMU 并正确地为 XRT 组件创建符号链接。该指南提供了安装依赖项、构建和安装 XRT 和 NPU 插件以及配置内存锁定限制的步骤说明,同时强调了避免使用 `amd_iommu=off` 内核参数的关键必要性。 AI
影响 支持在 AMD NPU 上运行 LLM,可能扩展 AI 推理的硬件选项。
排序理由 关于为特定任务设置特定硬件和软件的指南。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →