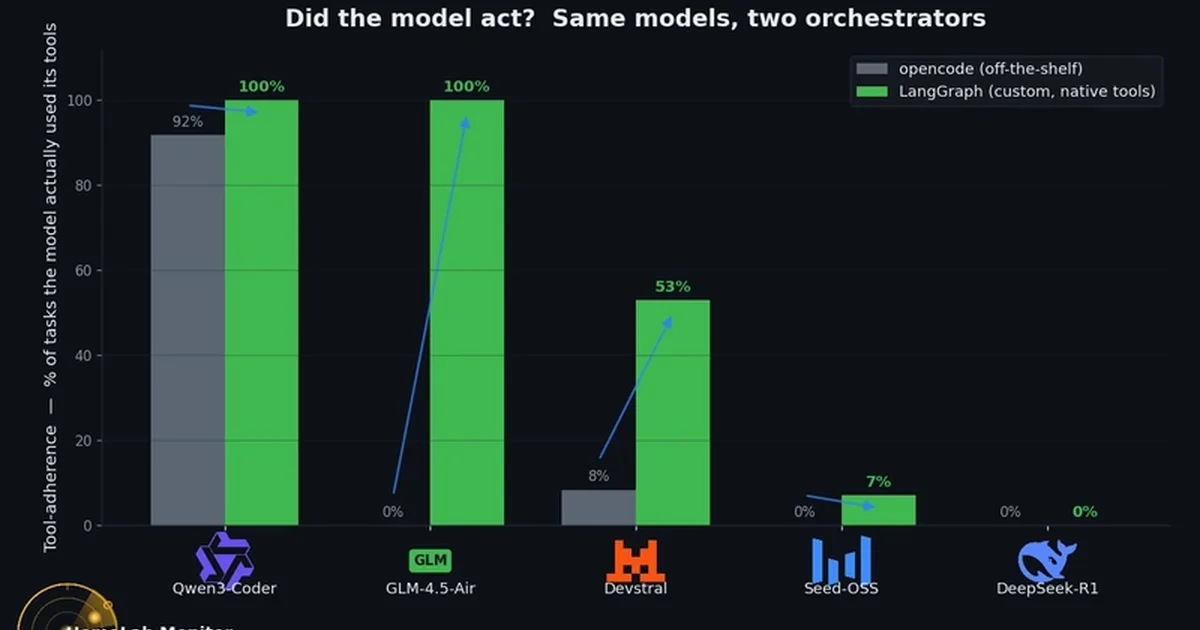
一项基准研究在RTX 3090 GPU上评估了五个本地LLM模型,重点关注它们在不同编排框架下的性能。研究发现,框架的选择,特别是支持原生工具调用(如LangGraph)的框架,显著影响模型的有效性,其中一个模型在使用合适的代理时,成功率从0%提高到93%。研究还强调了工具遵循的重要性,并测量了每项正确任务的电力成本,确定Qwen3-Coder是本地代理任务的高效模型。 AI
影响 强调了代理编排在释放本地应用LLM潜力中的关键作用。
排序理由 基准研究,比较LLM模型和编排框架。
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →