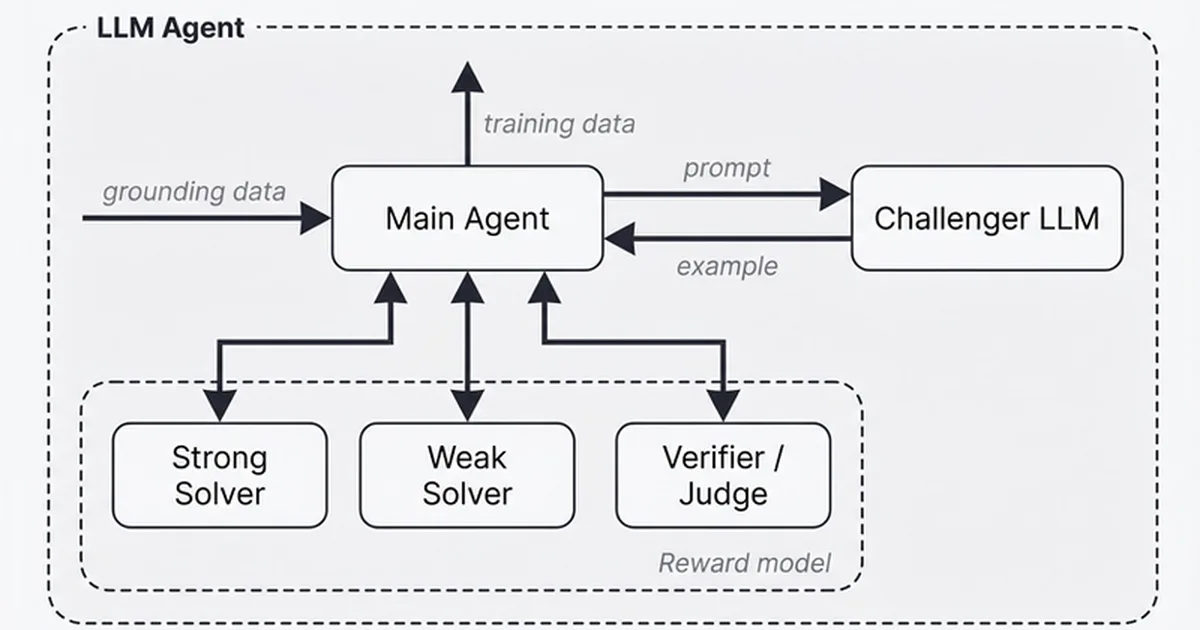
Meta FAIR开发的一种名为Autodata的新方法表明,一个参数量显著更小的40亿模型在特定任务上可以超越一个参数量大得多的3970亿模型。这种改进并非通过架构更改实现,而是通过优化数据生成过程。Autodata使用一个带有多个子代理的协调器代理来创建精确校准目标模型学习能力的训练数据,确保难度平衡,从而促进有效的梯度下降。 AI
影响 表明优化训练数据生成可以带来显著的性能提升,可能减少对超大规模模型的需求。
排序理由 详细介绍LLM新型数据生成方法的 ist 研究论文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →