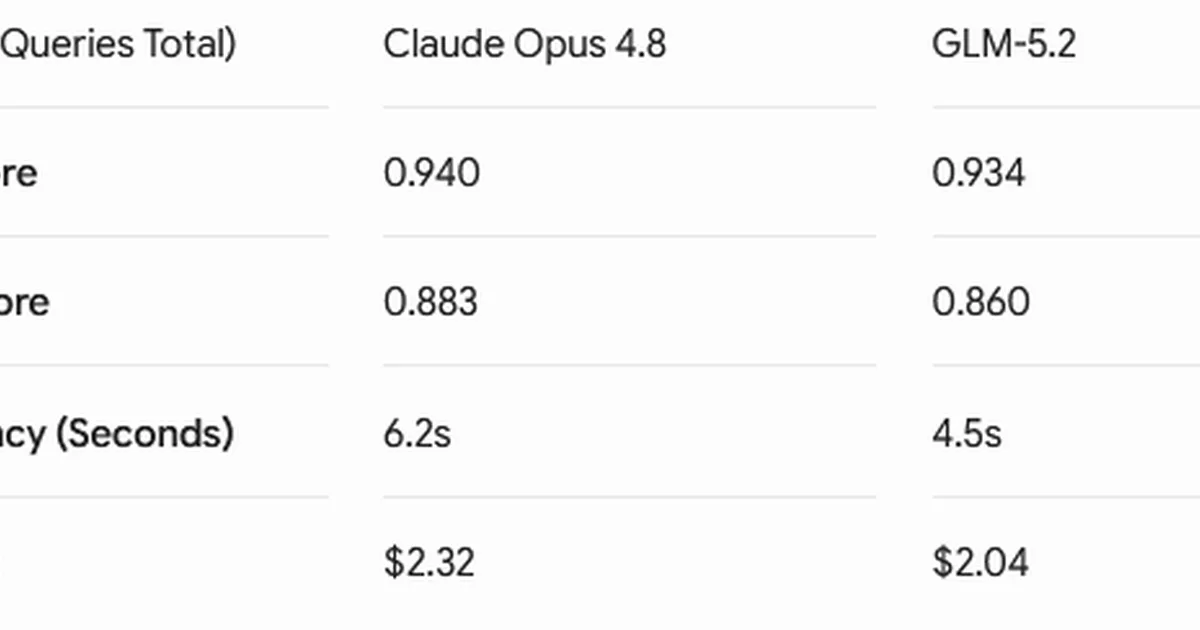
一项个人基准测试将 GLM-5.2 与 Anthropic 的 Claude Opus 4.8 的成本效益进行了比较。分析表明,GLM-5.2 可能为某些任务提供更经济的选择。作者质疑人工智能模型是否通常仅根据其标示价格来选择。 AI
影响 表明 GLM-5.2 可能是在某些应用中比 Claude Opus 4.8 更具成本效益的替代方案。
排序理由 该条目是一篇个人基准测试和观点文章,比较了两个人工智能模型,而不是主要发布或重要的行业事件。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →