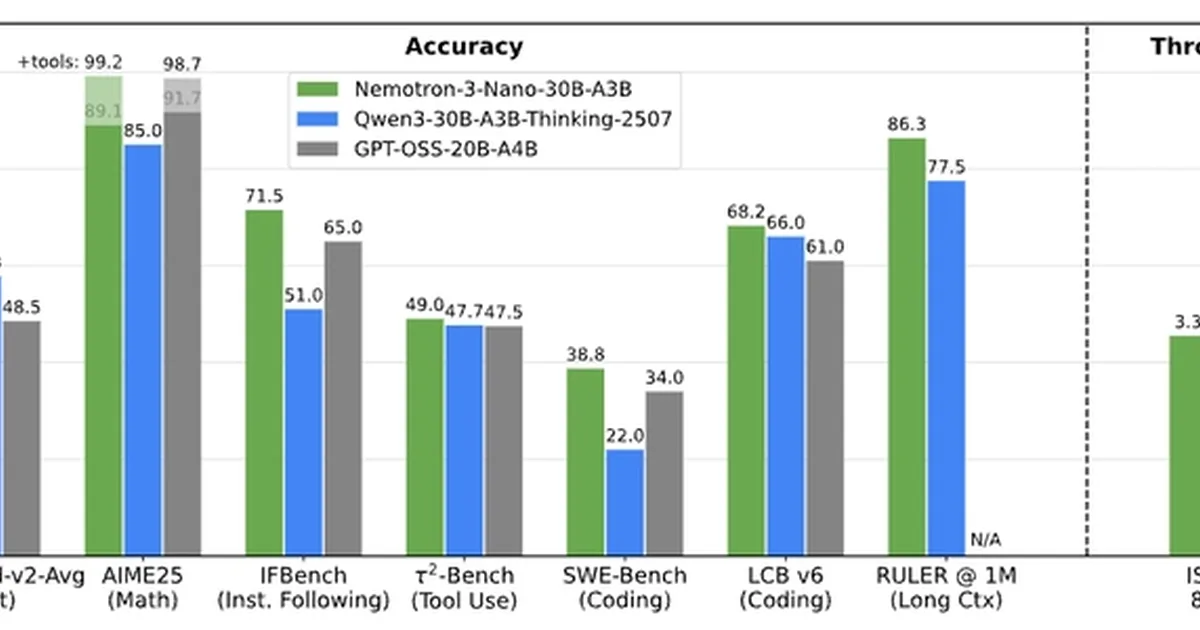
NVIDIA 发布了 Nemotron 3 Nano,这是一个拥有 300 亿参数的开放模型,专为高效推理和长上下文应用而设计。该模型采用了混合专家混合(Mixture-of-Experts)架构,每个 token 只激活其参数的一小部分,从而降低了强大推理性能的运营成本。Nemotron 3 Nano 在推理、编码和代理工作流基准测试中表现出竞争力,使其适用于构建需要处理大型文档或复杂任务的 AI 代理、编码助手和 RAG 系统的开发者。 AI
影响 使开发者能够更高效地部署先进的推理和代理能力。
排序理由 NVIDIA Nemotron 3 Nano:用于高效 AI 代理的开放模型。 [lever_c_demoted from frontier_release: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →