研究人员正在质疑用于评估大型语言模型(LLM)越狱的自动化评分系统的可靠性。一项新研究发现,专用分类器倾向于过度标记攻击,而基于LLM的裁判则表现出不一致的召回率,导致所使用的裁判不同,攻击成功率差异很大。这些自动化裁判也容易受到对抗性攻击,简单的文本操纵会显著改变其分数,而专用分类器则更具鲁棒性,但可能被白盒攻击所破坏。研究结果表明,许多报告的攻击成功率可能由于这些自动化评估方法的局限性而不可靠。 AI
影响 强调了在LLM安全研究中需要更强大、更可靠的评估指标,这可能会影响模型安全性的评估方式。
排序理由 该集群包含讨论评估LLM越狱和ASR错误自动化系统局限性和评估的研究论文。
- OpenAI
- Whisper
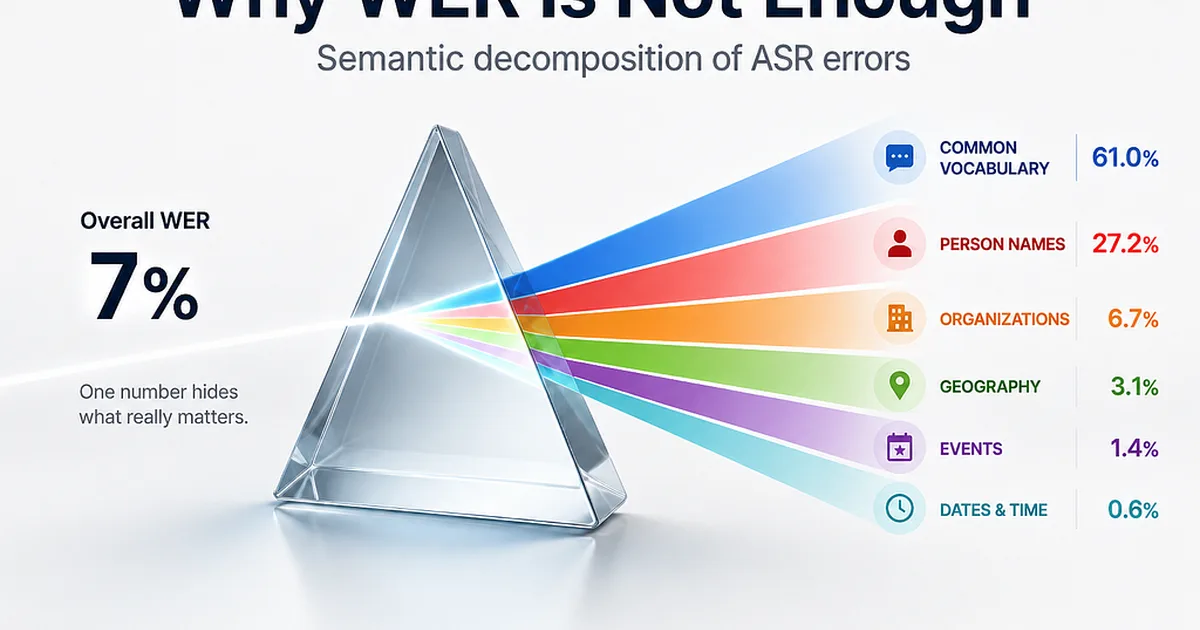
- word error rate
- alphaXiv
- arXiv
- DagsHub
- Greedy Coordinate Gradient
- HarmBench
- Hugging Face
- LLM
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →