这篇博文深入探讨了为什么深度神经网络尽管拥有众多参数,却仍能很好地泛化到新数据的问题。它探讨了奥卡姆剃刀原理和最小描述长度(MDL)原理等经典原则,这些原则表明更简单的模型更有可能是正确的,并且学习可以被视为数据压缩。特别是,MDL 原理将一个好的模型不仅应该解释数据,而且应该简洁,从而有助于泛化的想法形式化。 AI
排序理由 这是一篇讨论与机器学习泛化相关的理论概念和经典论文的博文。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
这篇博文深入探讨了为什么深度神经网络尽管拥有众多参数,却仍能很好地泛化到新数据的问题。它探讨了奥卡姆剃刀原理和最小描述长度(MDL)原理等经典原则,这些原则表明更简单的模型更有可能是正确的,并且学习可以被视为数据压缩。特别是,MDL 原理将一个好的模型不仅应该解释数据,而且应该简洁,从而有助于泛化的想法形式化。 AI
排序理由 这是一篇讨论与机器学习泛化相关的理论概念和经典论文的博文。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
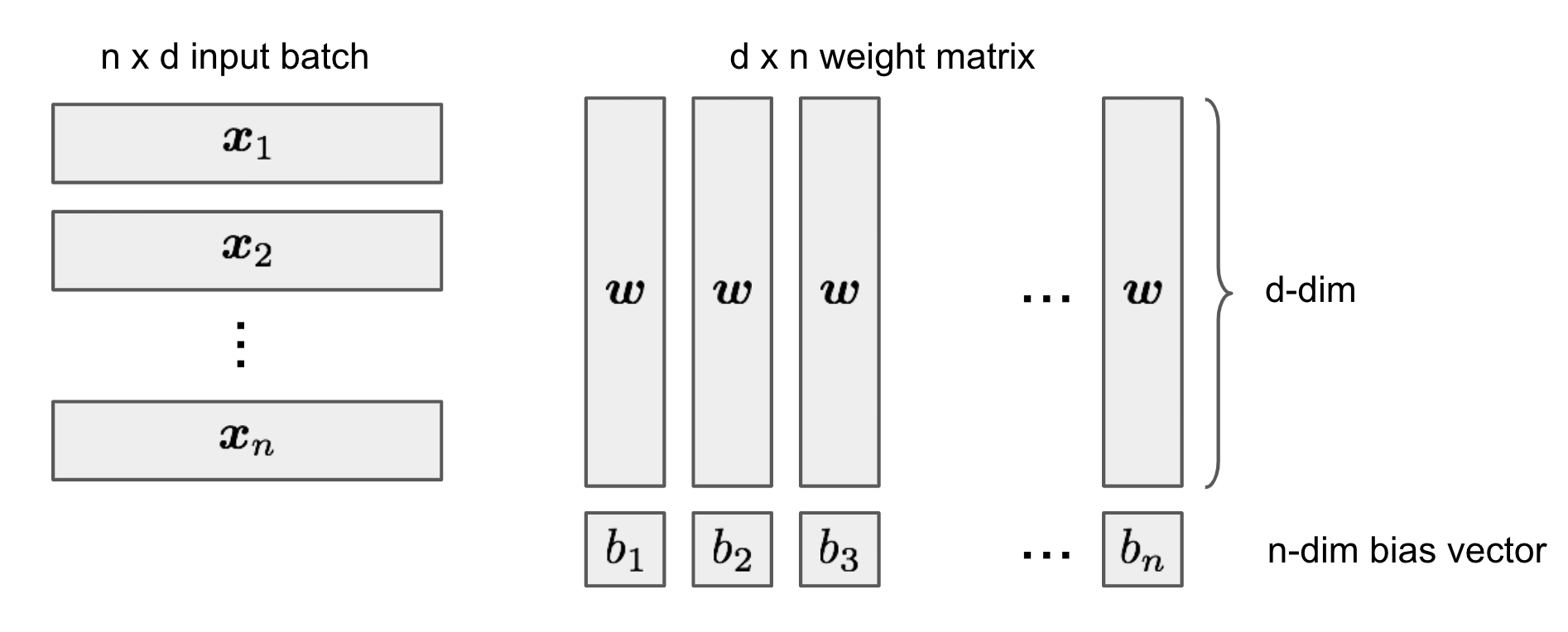
<!-- If you are, like me, confused by why deep neural networks can generalize to out-of-sample data points without drastic overfitting, keep on reading. --> <p><span class="update">[Updated on 2019-05-27: add the <a href="#the-lottery-ticket-hypothesis">section</a> on Lottery Tic…