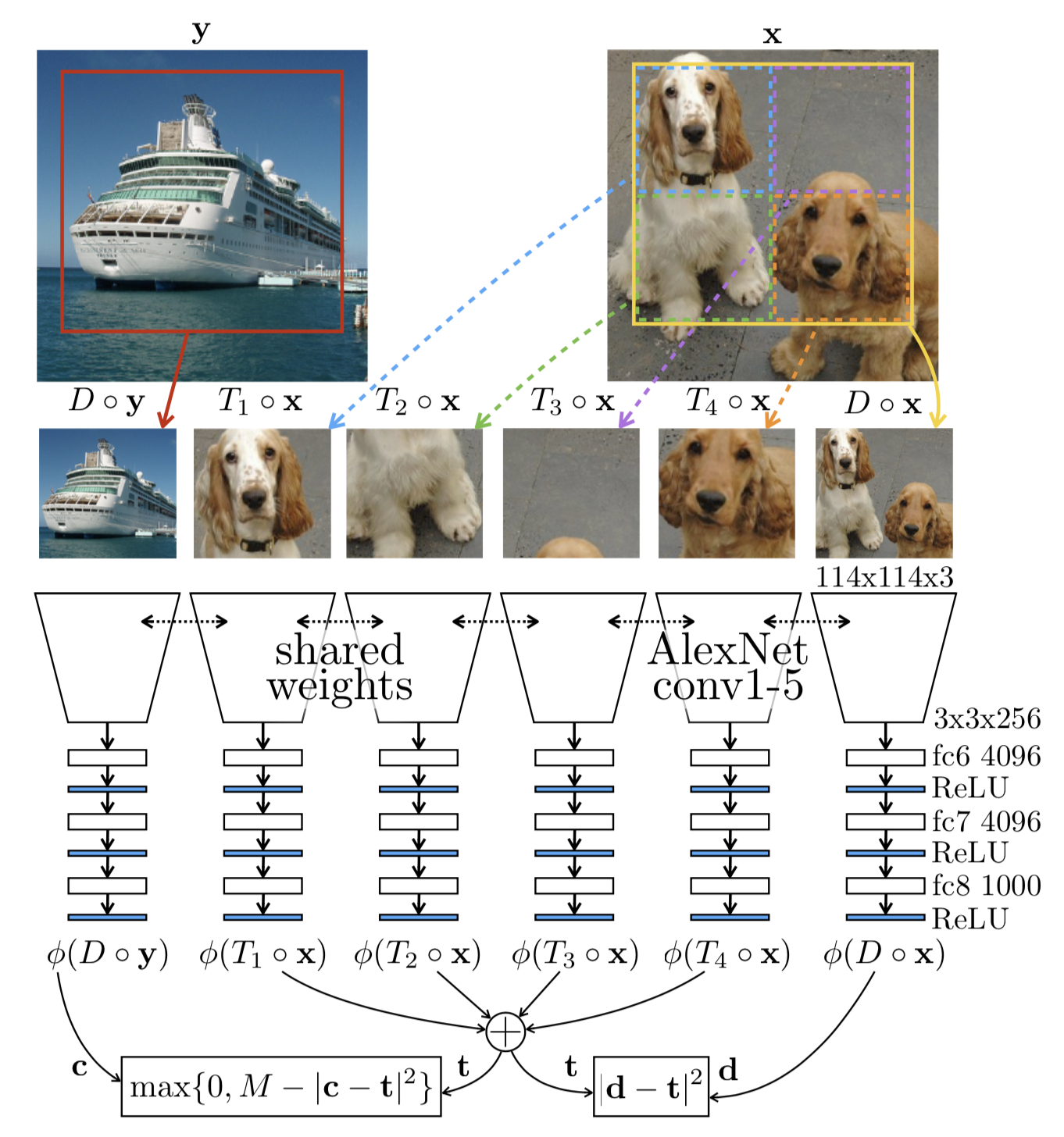
这篇博文探讨了自监督学习,这是一种利用现成可用无标签数据的方法,通过从数据本身创建监督任务来实现。核心思想是在这些“借口”任务上训练模型,并非为了任务本身,而是为了学习对各种下游应用有用的中间表示。这种方法解决了手动数据标注的高成本和可扩展性有限的问题,使得能够利用大量的无标签文本和图像。该博文强调了其在语言建模中的应用,并讨论了基于图像的自监督学习技术。 AI
排序理由 该条目是一篇总结自监督学习研究论文的博客文章。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →