这篇博文探讨了控制大型语言模型输出的方法,这些模型通常在海量的无监督网络数据上进行训练。目前的方法旨在不改变其核心权重的情况下引导这些模型,重点关注诸如引导解码策略和提示设计等技术。虽然这些方法提供了影响生成文本属性(如主题和风格)的方式,但作者指出,真正的模型可控性仍然是一个活跃的研究领域,并且正在持续探索各种优缺点。 AI
排序理由 该条目是一篇讨论可控文本生成研究的博文,引用了学术论文和技术。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
这篇博文探讨了控制大型语言模型输出的方法,这些模型通常在海量的无监督网络数据上进行训练。目前的方法旨在不改变其核心权重的情况下引导这些模型,重点关注诸如引导解码策略和提示设计等技术。虽然这些方法提供了影响生成文本属性(如主题和风格)的方式,但作者指出,真正的模型可控性仍然是一个活跃的研究领域,并且正在持续探索各种优缺点。 AI
排序理由 该条目是一篇讨论可控文本生成研究的博文,引用了学术论文和技术。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
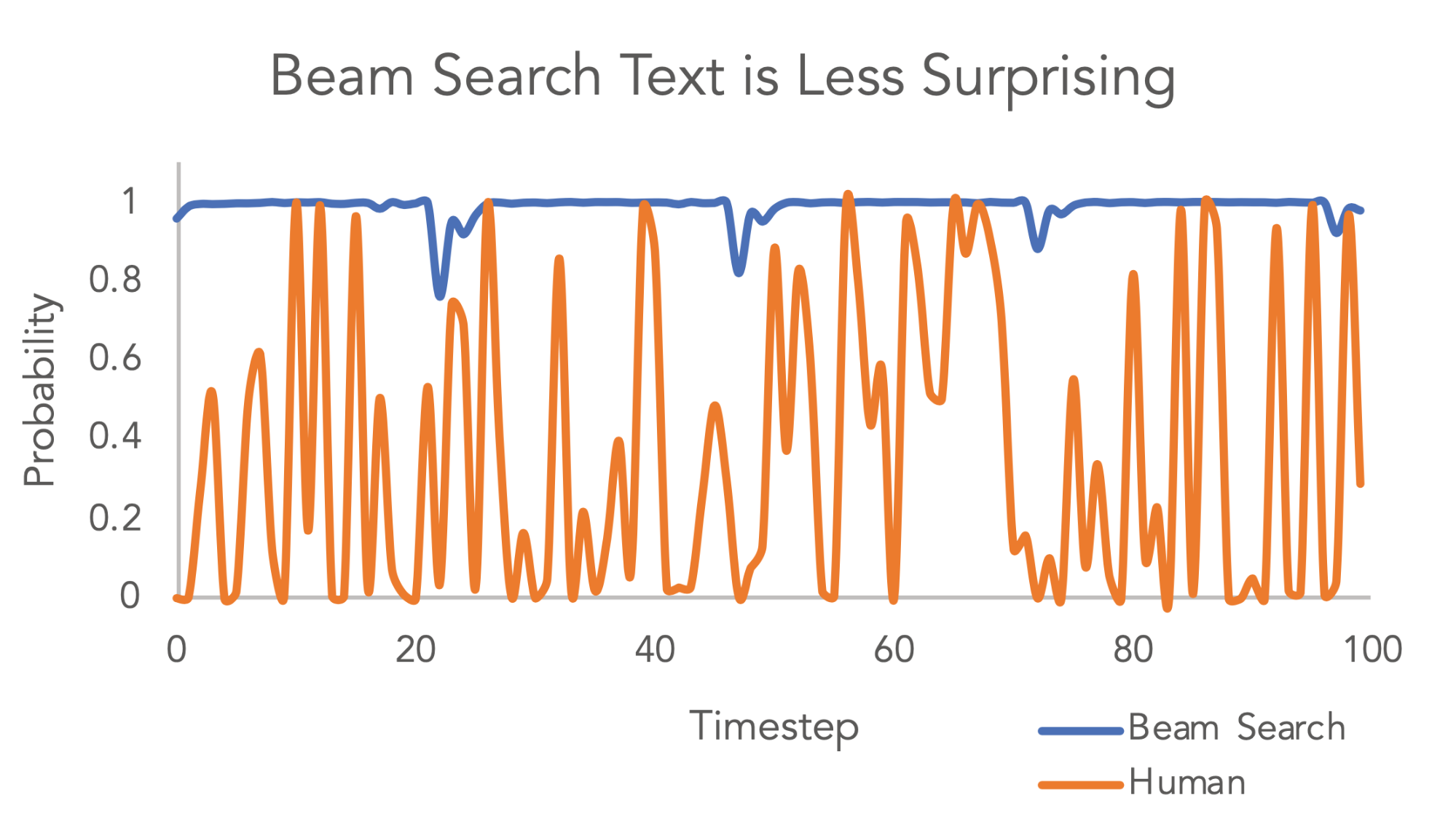
<!-- The modern language model with SOTA results on many NLP tasks is trained on large scale free text on the Internet. It is challenging to steer such a model to generate content with desired attributes. Although still not perfect, there are several approaches for controllable t…