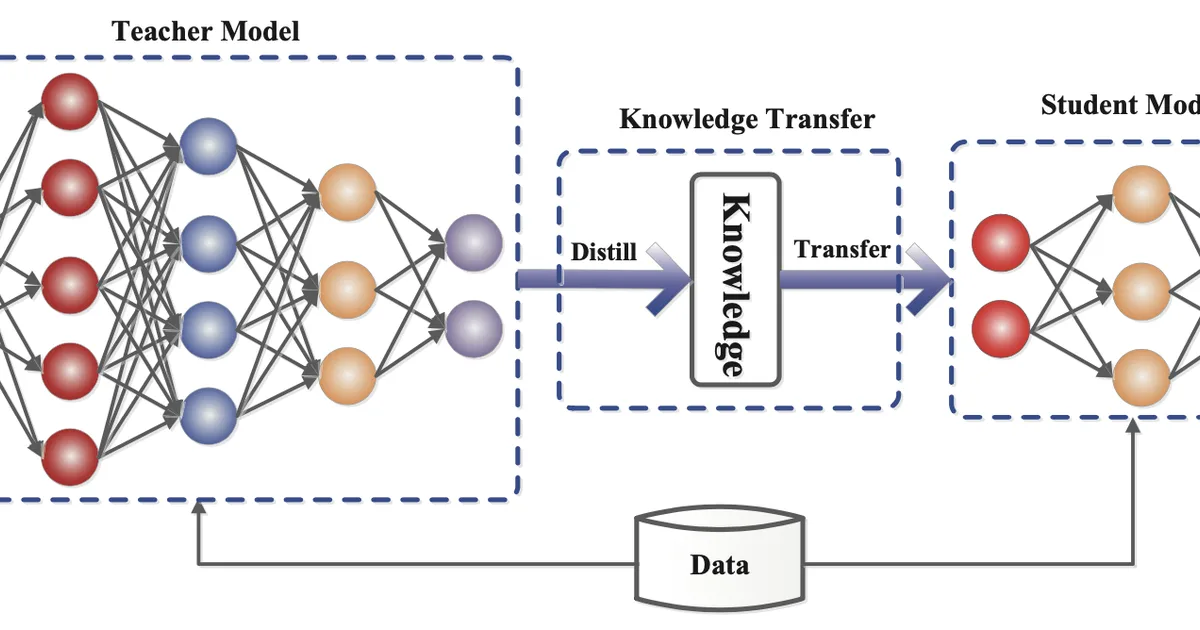
大型Transformer模型因其巨大的内存占用和计算成本,给推理带来了显著挑战,这些成本随输入长度呈二次方增长。研究人员和从业者正在探索各种优化技术来缓解这些问题。这些方法包括网络压缩策略,如剪枝、量化和知识蒸馏,以及架构改进和高效并行。目标是减少内存使用、计算复杂度和推理延迟,以实现实际的大规模部署。 AI
排序理由 该集群关注一篇技术博客文章和一次Reddit讨论,详细介绍了优化Transformer模型推理的方法,这属于研发范畴,而非新发布或重要的行业事件。
- GPTQ
- FP16
- Hugging Face
- Knowledge Distillation
- Lilian Weng
- LoRA
- ONNX
- Optimum
- SmoothQuant
- TensorRT
- Transformers Pipelines
- FlashAttention
AI 生成摘要 · Google Gemini · 来自 4 个来源。 我们如何撰写摘要 →