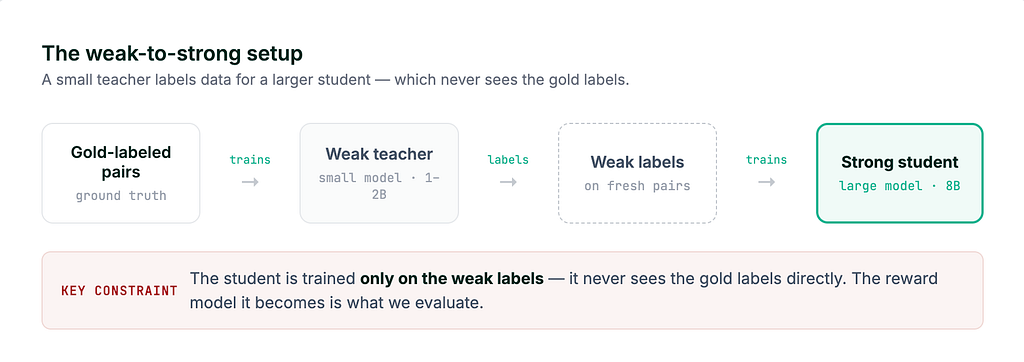
来自新加坡国立大学(NUS)、VinUniversity 和南洋理工大学(NTU)的一项新研究调查了弱到强奖励模型,发现模型在训练数据集上的高表现并不能保证其泛化到新的、未见过数据的能力。研究人员确定了表示漂移(representation drift)为一个关键问题,并提出了一种名为表示锚定(Representation Anchoring)的解决方案来缓解它。他们的发现表明,使用像RAIL数据集这样多样化、以价值观为基础的基准对于准确评估模型真正的无害性至关重要。 AI
影响 强调了人工智能安全需要超越分布内表现的鲁棒评估方法。
排序理由 学术论文,详细介绍了对奖励模型的研究并提出了一种新技术。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →