研究人员正在开发新方法来增强大型语言模型(LLM)在对抗性攻击下的安全性和鲁棒性。这些攻击通常以精心设计的提示形式出现,旨在绕过内置的安全机制并产生不良输出。努力包括创建 AprielGuard 等护栏,并开发排行榜来跟踪和改进模型对此类漏洞的安全性。 AI
排序理由 这些条目讨论了与 LLM 安全性和对抗性攻击相关的研究论文和框架,符合“研究”类别。
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →
研究人员正在开发新方法来增强大型语言模型(LLM)在对抗性攻击下的安全性和鲁棒性。这些攻击通常以精心设计的提示形式出现,旨在绕过内置的安全机制并产生不良输出。努力包括创建 AprielGuard 等护栏,并开发排行榜来跟踪和改进模型对此类漏洞的安全性。 AI
排序理由 这些条目讨论了与 LLM 安全性和对抗性攻击相关的研究论文和框架,符合“研究”类别。
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →
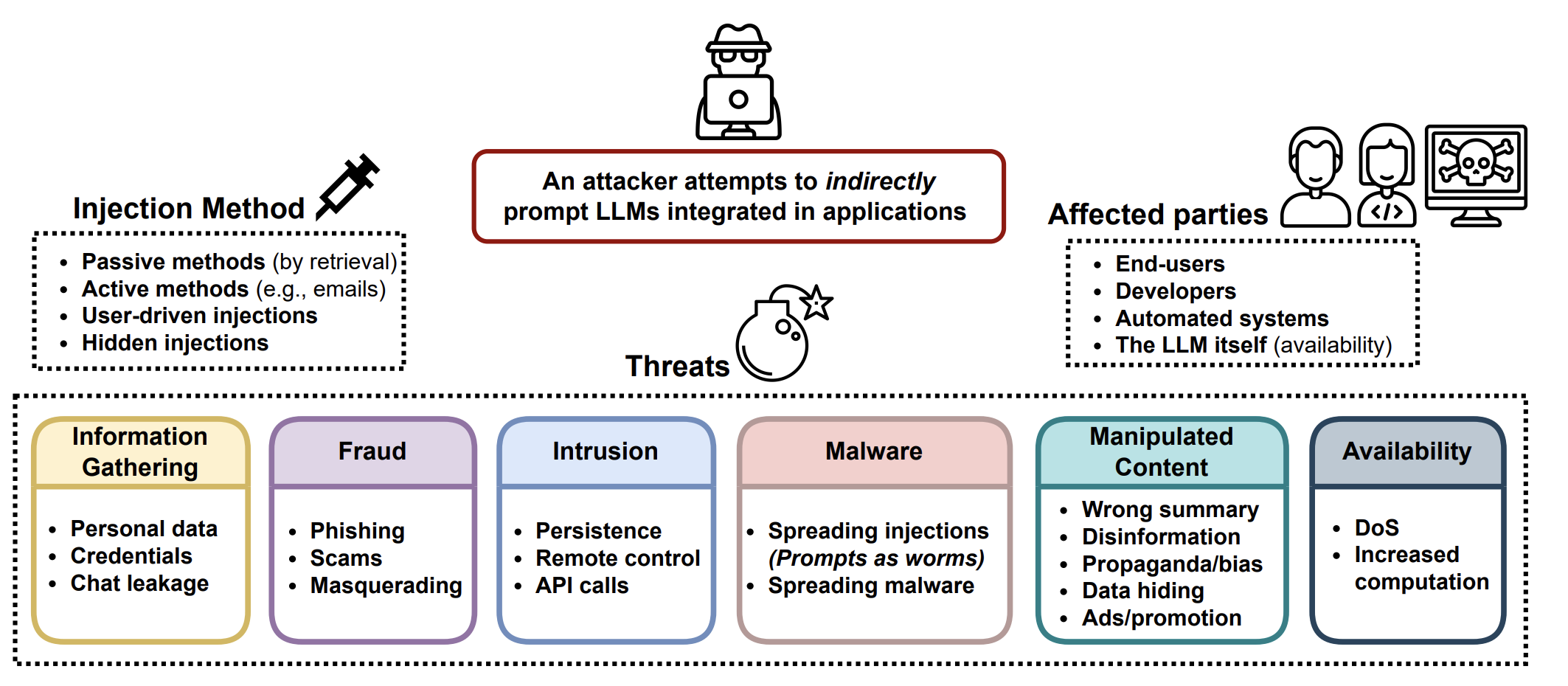
<p>The use of large language models in the real world has strongly accelerated by the launch of ChatGPT. We (including my team at OpenAI, shoutout to them) have invested a lot of effort to build default safe behavior into the model during the alignment process (e.g. via <a href="…