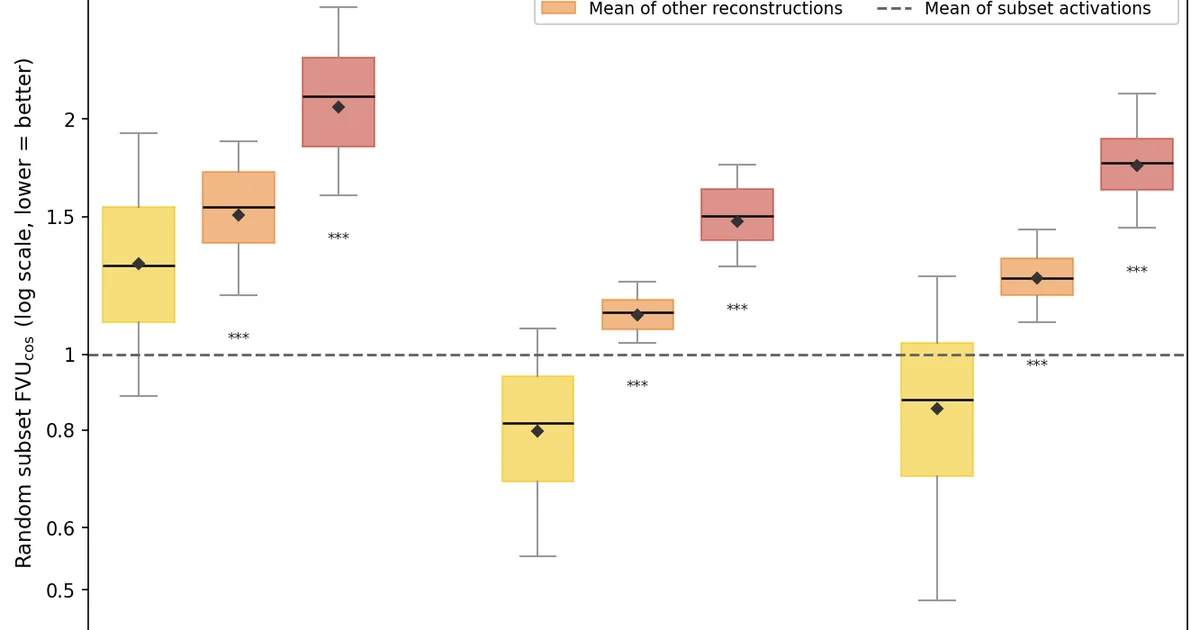
Researchers have evaluated activation verbalizers (AVs) to determine if they can reliably surface a target model's internal reasoning process during a single forward pass, particularly for math problems. The study applied this evaluation to open-weight natural language autoencoders (NLAs) for models like Qwen2.5, Gemma, and Llama 3.3. Initial findings suggest that these NLAs are not yet proficient enough at reconstruction to consistently track subtle differences in opaque reasoning, with some models performing worse than a simple baseline. AI
IMPACT New research suggests current methods for verbalizing AI model reasoning are unreliable, potentially hindering efforts to monitor complex internal thought processes.
RANK_REASON The cluster describes a research paper evaluating a new method for understanding AI model reasoning. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →