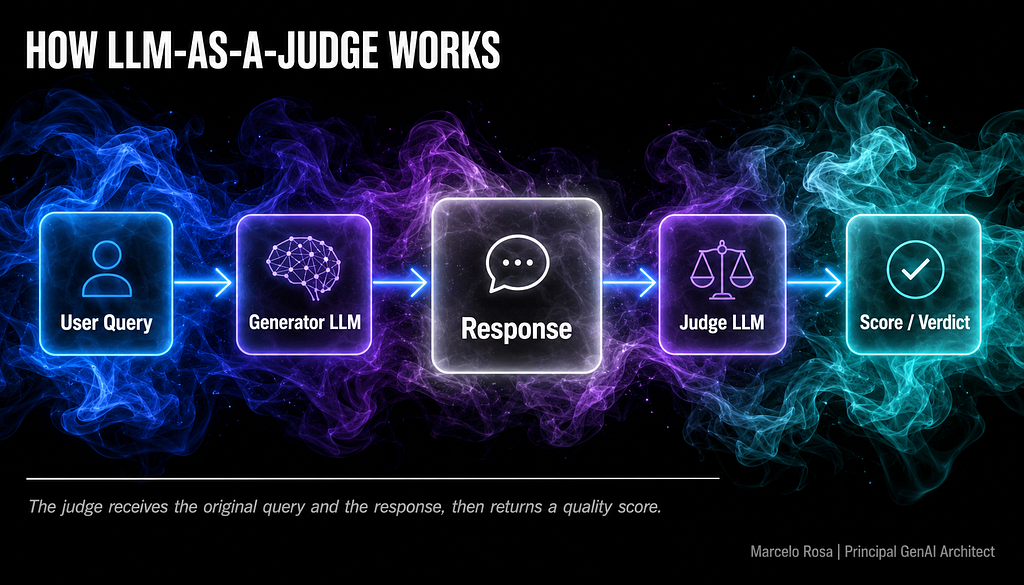
Evaluating large language models (LLMs) using another LLM, known as LLM-as-a-Judge, has become a common practice for scaling assessment. However, this method is prone to subtle biases that can distort results. The article identifies six such biases, including position bias where the order of responses influences the judge's decision, and length bias where longer answers are unfairly favored. Addressing these issues is crucial for ensuring the reliability of LLM evaluation pipelines. AI
IMPACT Highlights critical flaws in common LLM evaluation techniques, urging developers to implement bias mitigation strategies for more reliable model assessments.
RANK_REASON The article discusses research into biases within LLM evaluation methodologies. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →