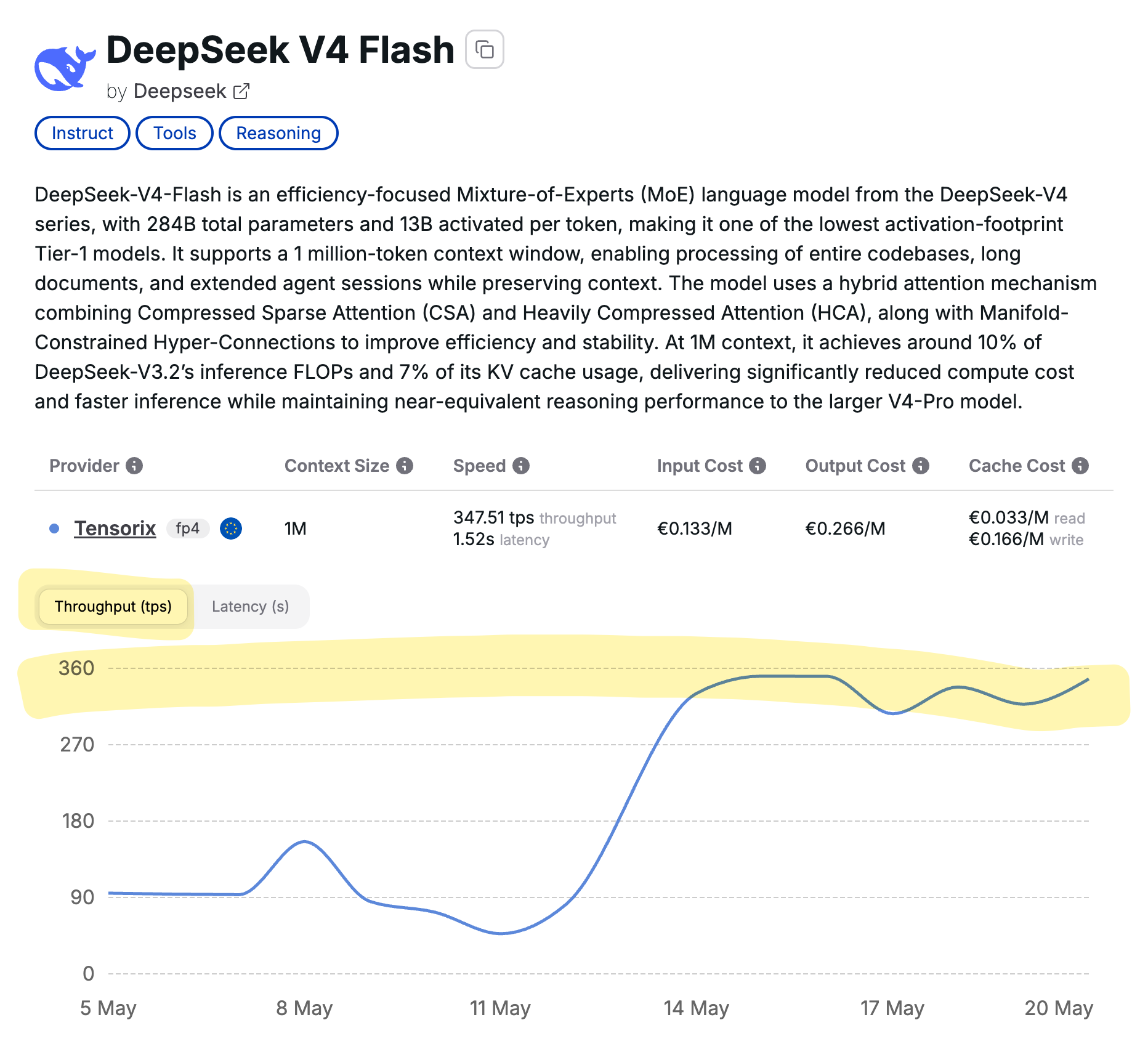
DeepSeek V4 Flash, a new iteration of the DeepSeek V4 model, has demonstrated impressive performance metrics. It achieves a throughput of 350 tokens per second with a latency of approximately 1.5 seconds. This advancement is attributed to Tensorix and Cortecs, with implications for AI development in the EU. AI
IMPACT New performance benchmarks for DeepSeek V4 Flash offer insights into LLM throughput and latency capabilities.
RANK_REASON The cluster details performance metrics for a specific AI model iteration, which falls under research milestones. [lever_c_demoted from research: ic=1 ai=1.0]
Read on Mastodon — fosstodon.org →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →