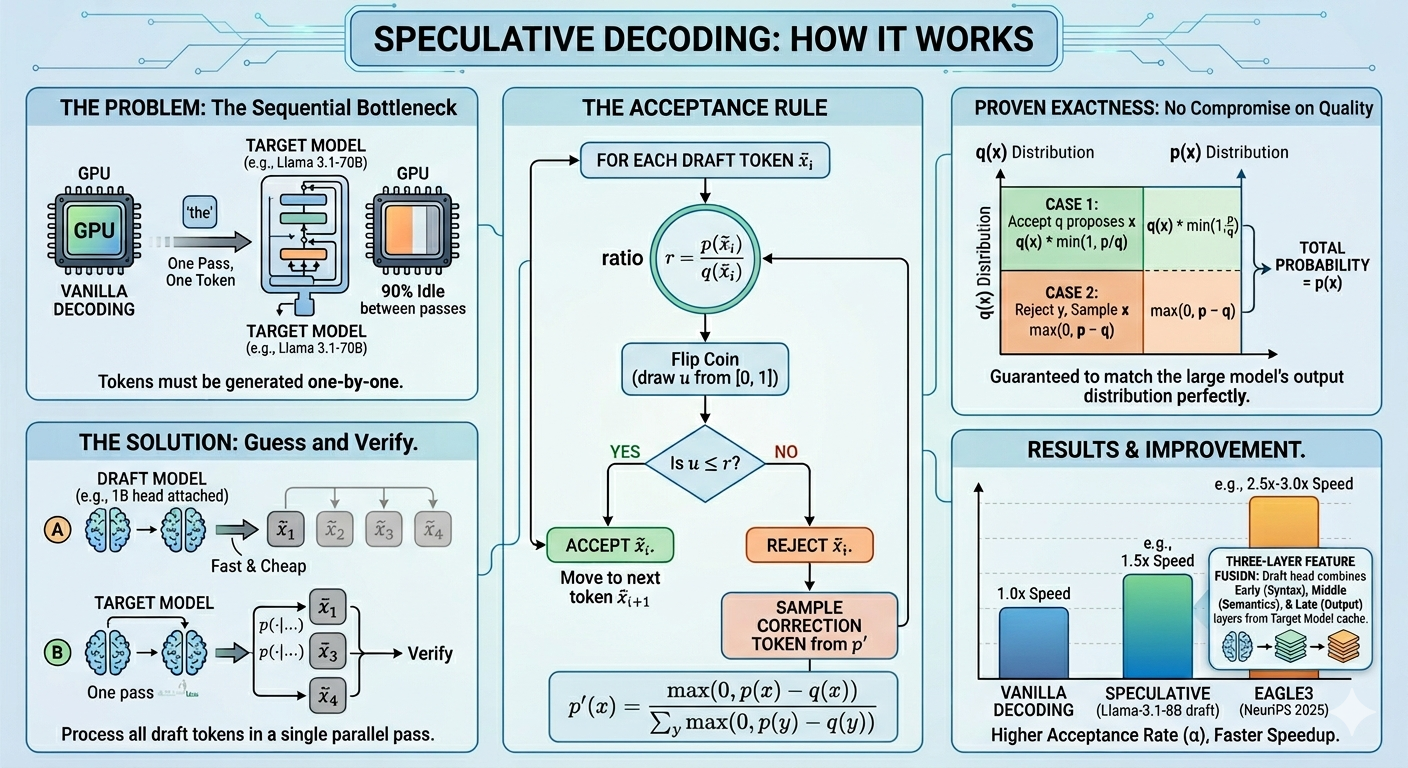
A new technique called speculative decoding allows large language models to generate text more efficiently by predicting ahead and then verifying. This method aims to reduce the computational cost of generating each token, which currently requires a full forward pass. By enabling LLMs to guess and check, the process could significantly speed up text generation. AI
IMPACT This technique could significantly reduce the computational cost of LLM inference, making them faster and more accessible.
RANK_REASON The cluster describes a new research technique for improving LLM efficiency. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →