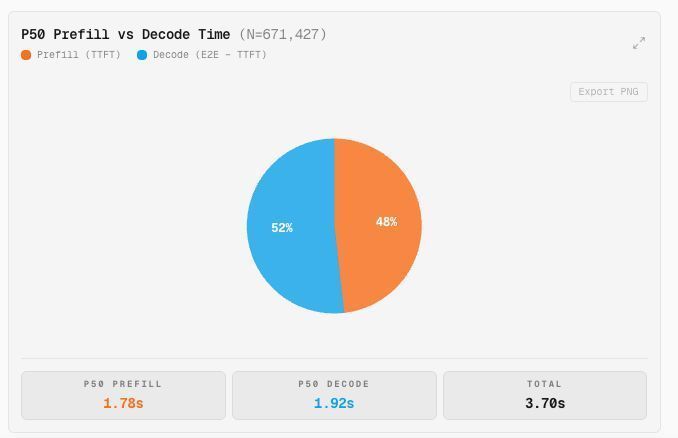
New analysis indicates that approximately 48% of end-to-end latency in large language models is attributed to the prefill stage, with the remaining 52% coming from the decoding process. The prefill stage is further divided into two operations: prefill extend, which involves writing new context and KV tokens, and cache read, which reuses existing KV cache from previous interactions. AI
IMPACT Understanding latency breakdown in LLMs is crucial for optimizing inference speed and cost.
RANK_REASON Analysis of LLM performance characteristics from a third-party source.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →