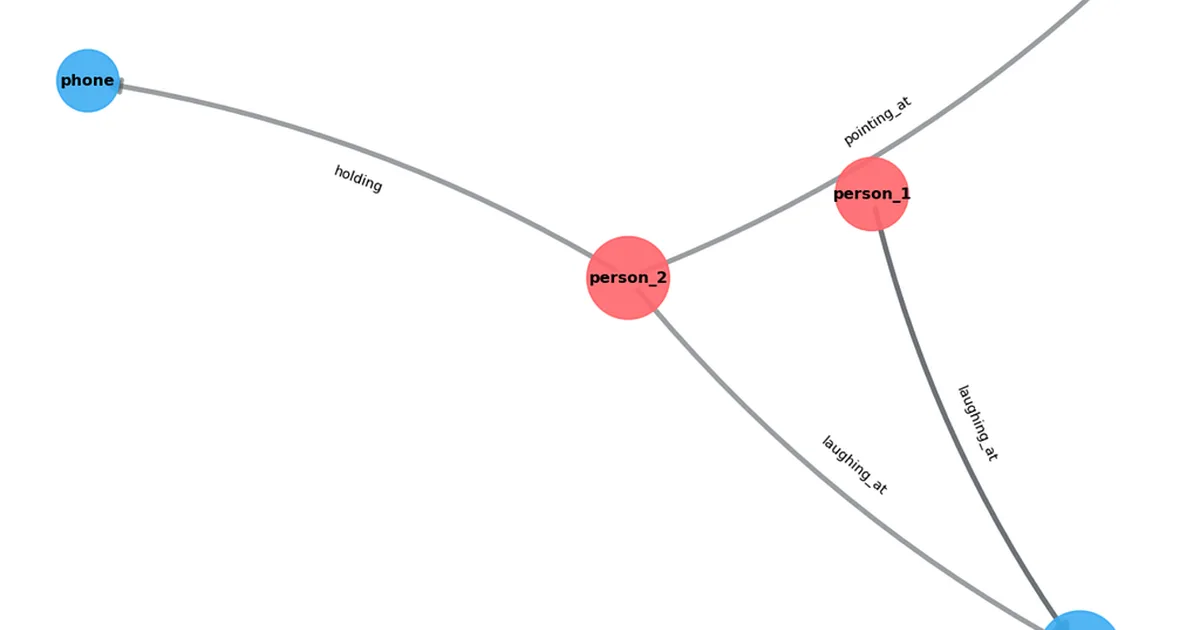
A new method for Video Scene Graph Generation (SGG) leverages Vision-Language Models (VLMs) to create structured, machine-readable descriptions of video content. Unlike traditional SGG methods that rely on fixed vocabularies, this approach uses open-vocabulary VLMs like Qwen2.5-VL to generate descriptions directly from visual and linguistic cues. The process involves selecting keyframes from a video and then using the VLM to identify objects, people, and their relationships, forming a graph that can be programmatically analyzed. AI
IMPACT Enables programmatic understanding of video content by generating structured, open-vocabulary scene graphs.
RANK_REASON The item describes a novel method for video scene graph generation using VLMs, including implementation details and code. [lever_c_demoted from research: ic=1 ai=1.0]
- AutoProcessor
- Kartikeya
- Medium
- NetworkX
- NumPy
- PyTorch
- Qwen2.5-VL
- Qwen2_5_VLForConditionalGeneration
- transformers
- Video Scene Graph Generation
- Vision--Language Models
- Visual Genome
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →