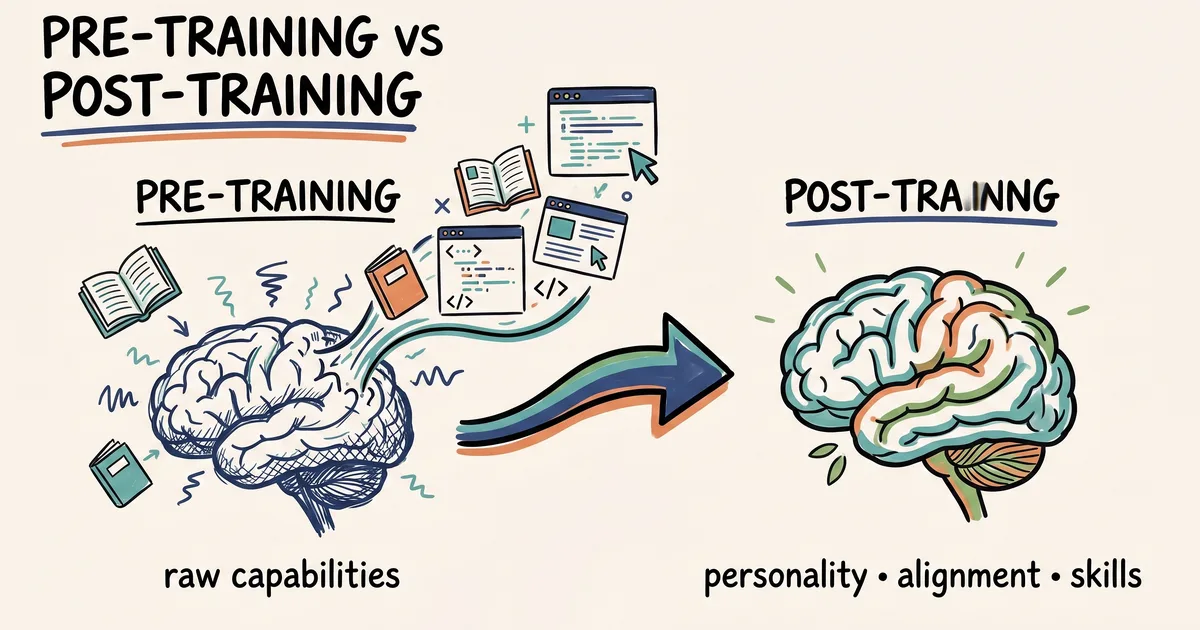
This article delves into supervised fine-tuning (SFT), a crucial post-training technique for large language models. It explains how SFT shapes a raw language model's behavior, making it more aligned with desired outputs and functionalities. The piece serves as the first part in a series exploring different post-training methodologies. AI
IMPACT Explains a core technique for aligning LLM behavior with user intent.
RANK_REASON The item is a technical explanation of a machine learning technique, fitting the research category. [lever_c_demoted from research: ic=1 ai=1.0]
Read on Medium — fine-tuning tag →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →