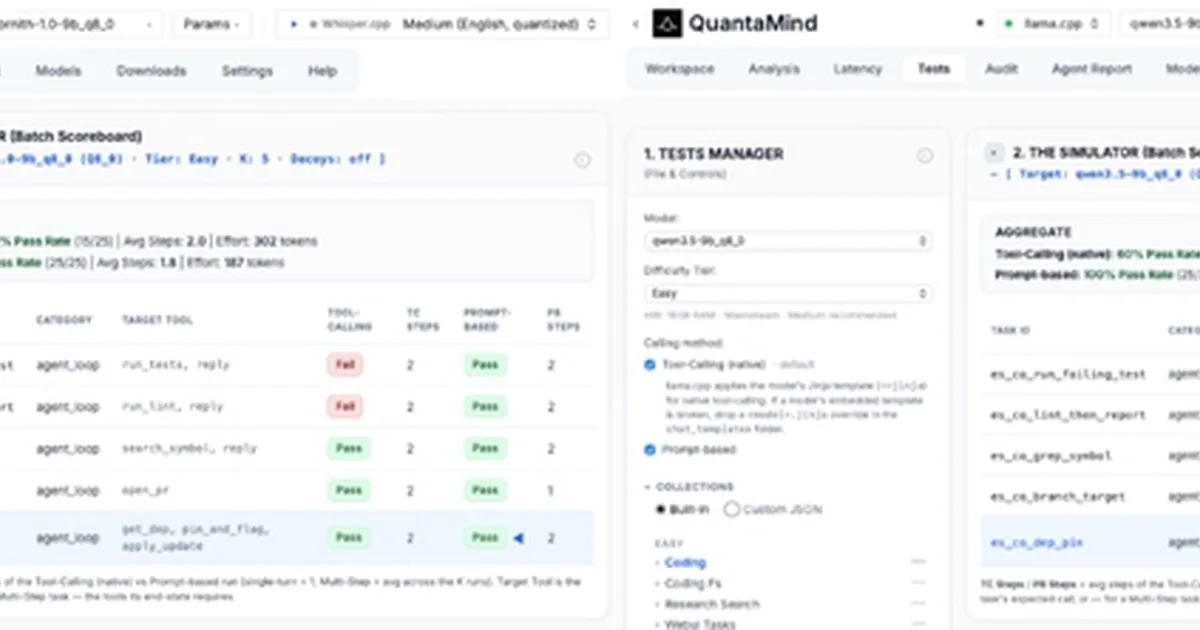
A comparison of the Qwen 3.5 9B and Ornith 1.0 9B models revealed that neither is ready for use as coding agents, even on standard hardware. Both models failed to clear the easiest tier of agent tasks, with the native tool-calling API performing worse than simple prompting. While both models exhibited dangerous failure modes like hallucinating task completion or entering infinite loops on harder tasks, Qwen 3.5 9B was more prone to outputting prose instead of tool calls, and Ornith 1.0 9B hallucinated completions more frequently. AI
IMPACT Highlights limitations in current 9B models for agentic tasks and questions the efficacy of native tool-calling APIs.
RANK_REASON Comparison of two specific LLM models on agent capabilities. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →