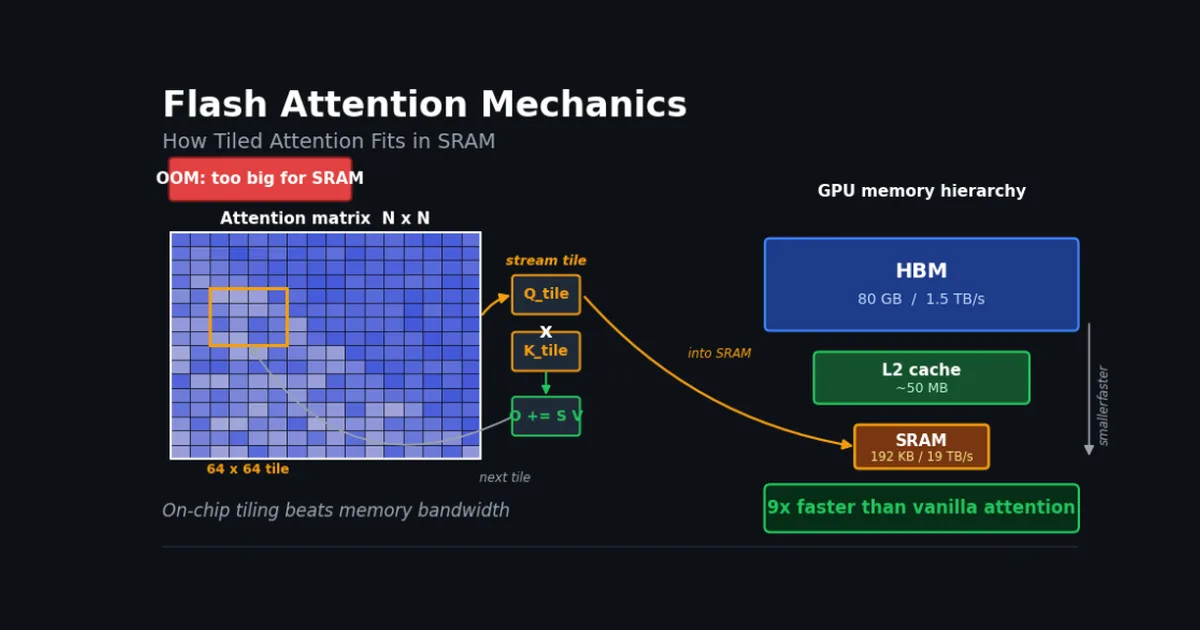
This article delves into the mechanics of Flash Attention, a technique designed to optimize the self-attention mechanism in AI models. It explains how tiled attention, a method for processing attention computations in smaller blocks, fits within the SRAM (Static Random-Access Memory) architecture. The explanation aims to clarify the underlying processes that make attention mechanisms more efficient. AI
IMPACT Explains optimizations for attention mechanisms, crucial for efficient large model training and inference.
RANK_REASON Article details a specific technical mechanism within AI infrastructure. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →