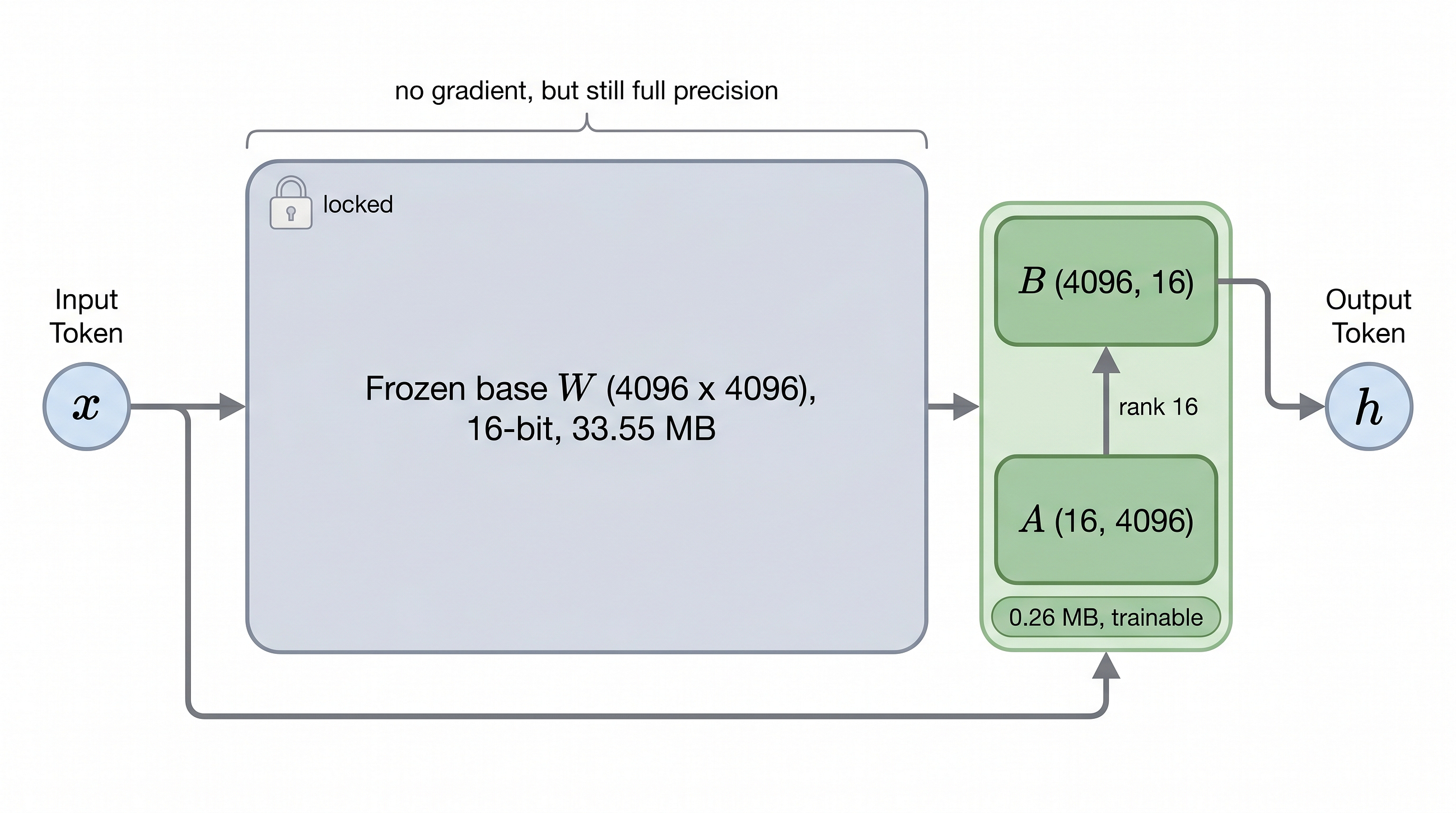
QLoRA, or Quantized Low-Rank Adaptation, is a technique that allows for the fine-tuning of large language models using significantly less memory. This method involves quantizing the model weights to 4-bit precision, effectively reducing their size by three-quarters while maintaining 16-bit precision for the adaptation parameters. This approach enables the fine-tuning of models with up to 65 billion parameters on a single GPU. AI
IMPACT Enables fine-tuning of large language models on consumer hardware, democratizing access to advanced AI customization.
RANK_REASON The item explains a specific research technique (QLoRA) for fine-tuning large language models. [lever_c_demoted from research: ic=1 ai=1.0]
Read on Medium — fine-tuning tag →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →