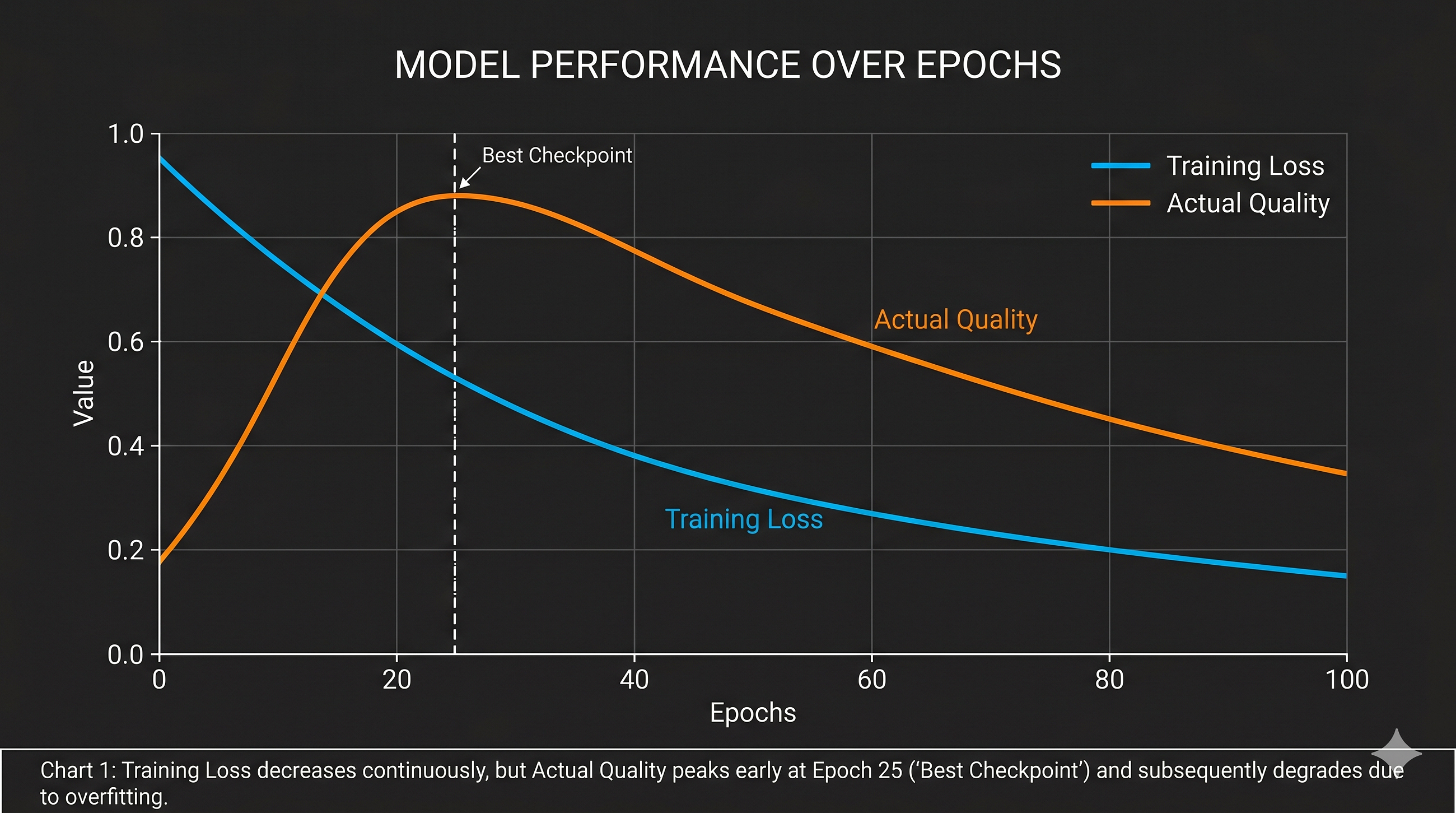
A developer's experience building a local AI companion revealed that the standard loss curve metric is often misleading during LLM fine-tuning. The author found that focusing on this metric alone led to suboptimal results, suggesting that alternative evaluation methods are crucial for effective fine-tuning. AI
IMPACT Highlights potential pitfalls in standard LLM fine-tuning practices, suggesting a need for more nuanced evaluation strategies.
RANK_REASON The item is an opinion piece or analysis from a developer about a technical aspect of LLM fine-tuning, not a primary release or research paper.
Read on Medium — fine-tuning tag →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →