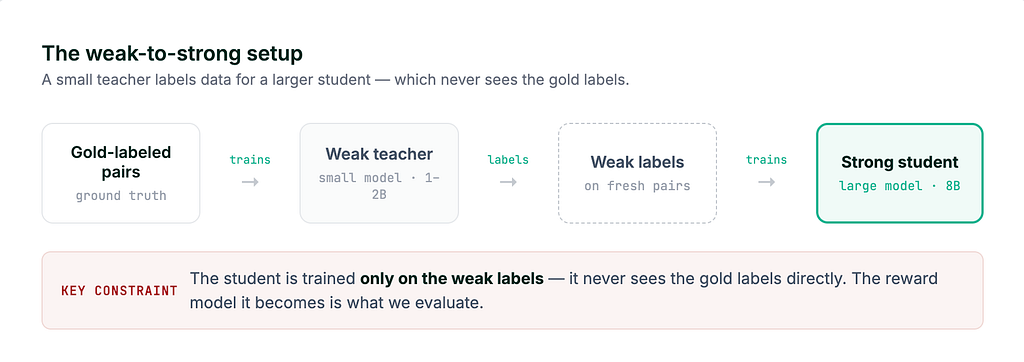
A new study from NUS, VinUniversity, and NTU investigated weak-to-strong reward models and found that high performance on a training dataset does not guarantee a model's ability to generalize to new, unseen data. The researchers identified representation drift as a key issue and proposed a solution called Representation Anchoring to mitigate it. Their findings suggest that using diverse, values-grounded benchmarks like the RAIL dataset is crucial for accurately evaluating a model's true harmlessness. AI
IMPACT Highlights the need for robust evaluation methods beyond in-distribution performance for AI safety.
RANK_REASON Academic paper detailing a study on reward models and proposing a new technique. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →