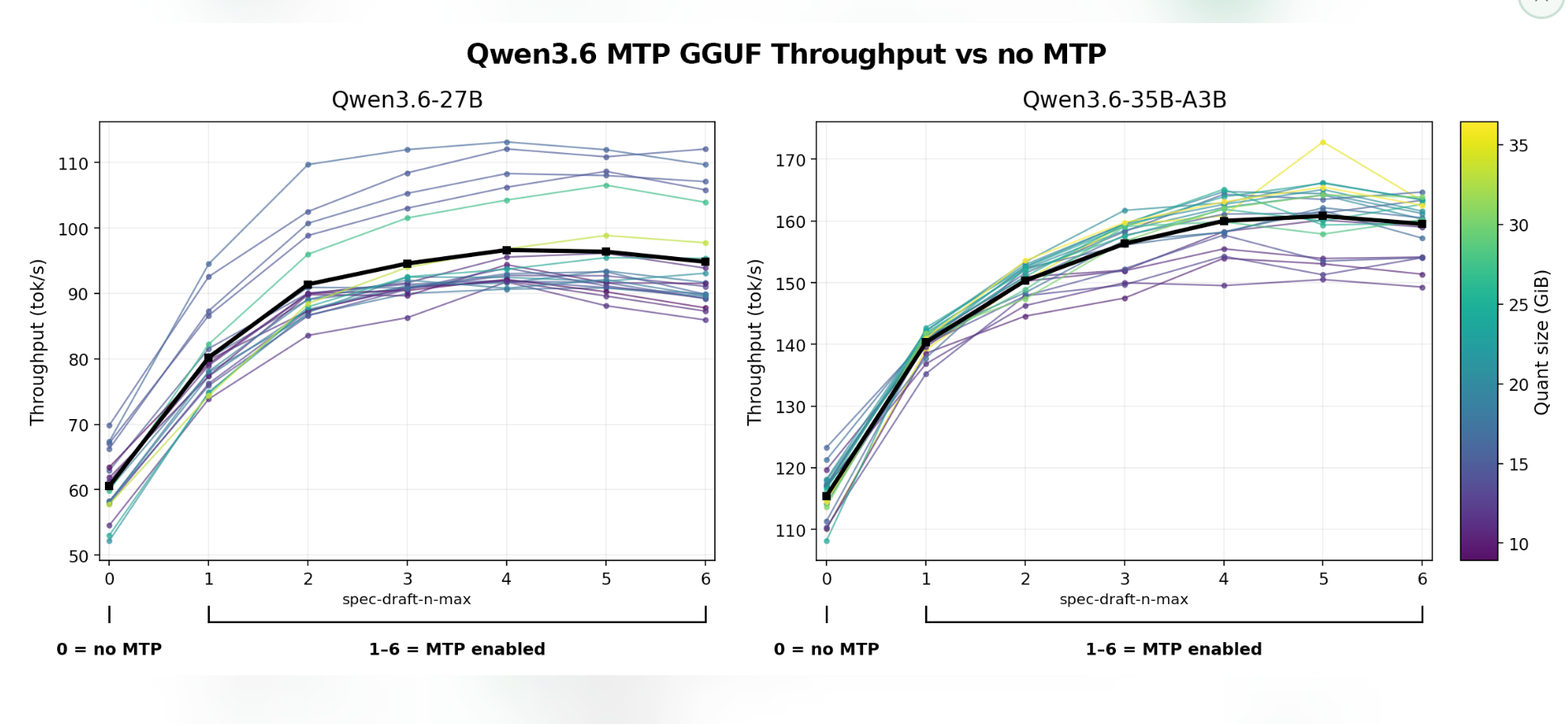
Qwen 3.6 27B and 35B MTP vs Standard on 16GB GPU
A technical analysis explores the performance of Qwen 3.6's 27B and 35B models when using Multi-Token Prediction (MTP), a speculative decoding technique. The tests, conducted on a 16GB VRAM GPU, reveal that MTP can significantly increase token generation speed by predicting multiple tokens per step. However, this speed boost comes at the cost of reduced context window size, particularly with higher MTP settings and certain quantization levels. AI
IMPACT Demonstrates how speculative decoding techniques like MTP can improve inference speed for large language models, albeit with trade-offs in context window size.