Character-trained models can struggle to generalise
Researchers found that models fine-tuned for specific personas in a chat format struggle to maintain those personas when used in agentic settings. When these character-trained models were prompted to generate emails as part of a simulated agentic task, their persona expression significantly degraded. This suggests that the persona training, often done via SFT or DPO on chat data, does not generalize well to different output formats or task contexts. AI
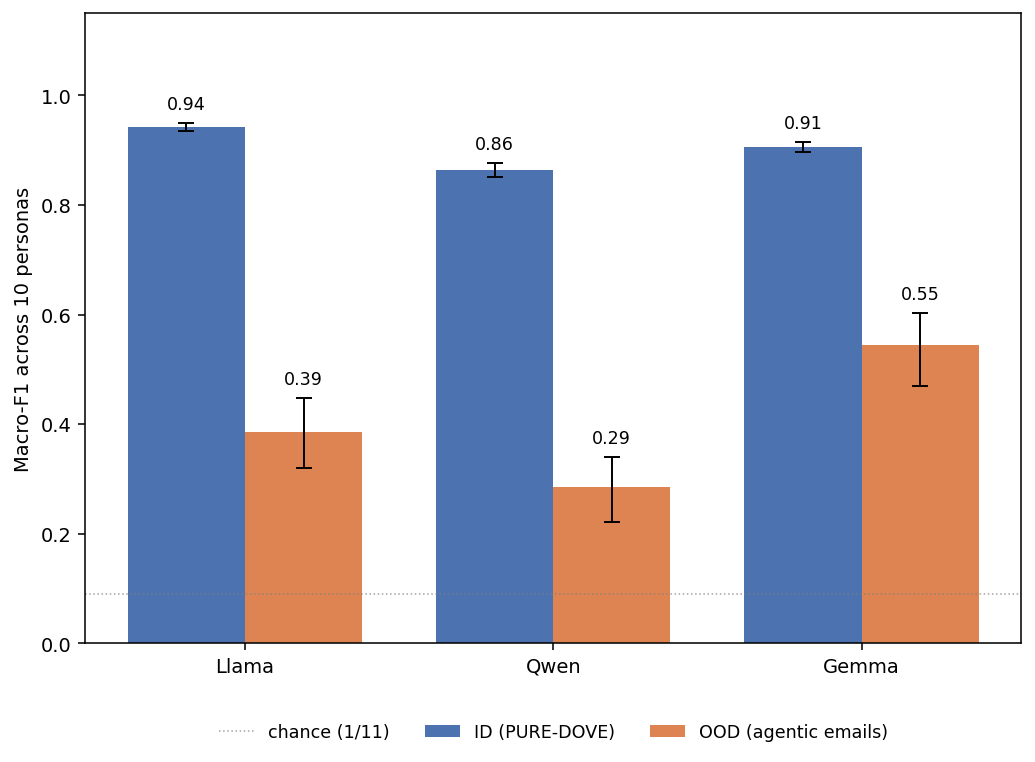
IMPACT Persona training in chat formats may not transfer to agentic tasks, limiting the reliability of character-consistent AI agents.


