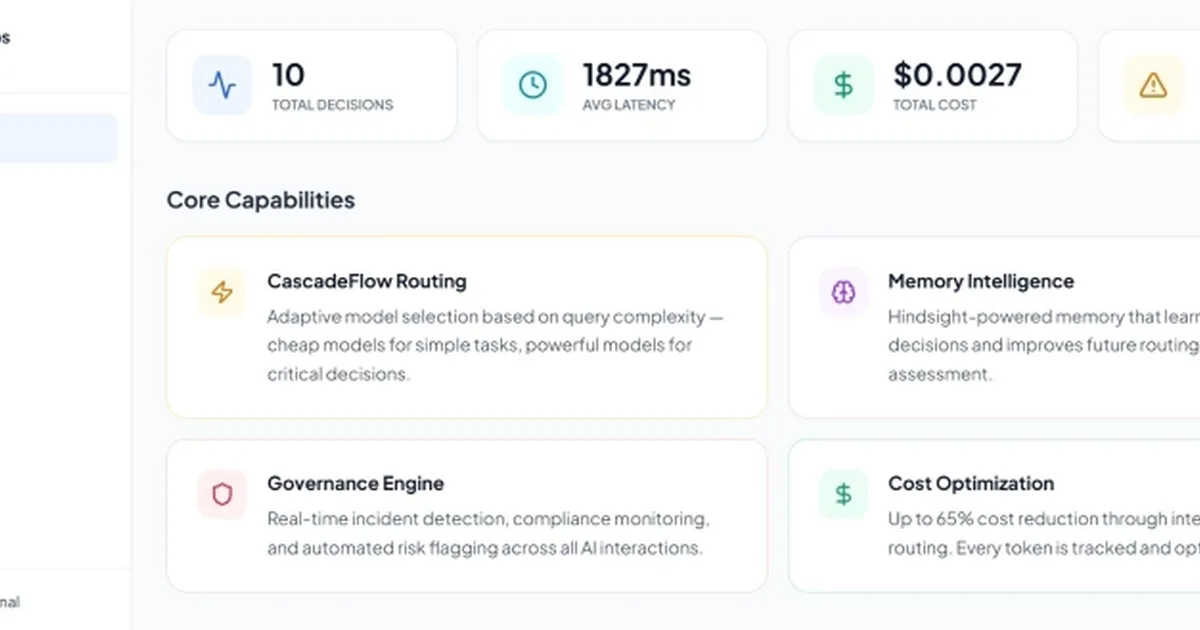
SentinelOps AI implemented a routing layer called CascadeFlow to optimize LLM inference costs. This system directs queries to different models based on complexity, sending simple lookups to a cheaper, faster 8B parameter model and complex operational or compliance questions to a more powerful 70B parameter model. This tiered approach reduced their AI inference bill by 65%, though initial misclassification rates required adjustments like keyword pre-checks and confidence thresholds to maintain accuracy for critical queries. AI
IMPACT Optimizing LLM inference costs through tiered routing can significantly reduce operational expenses for AI-powered applications.
RANK_REASON The article describes the implementation of a new feature/system within an existing product to improve efficiency and reduce costs.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →