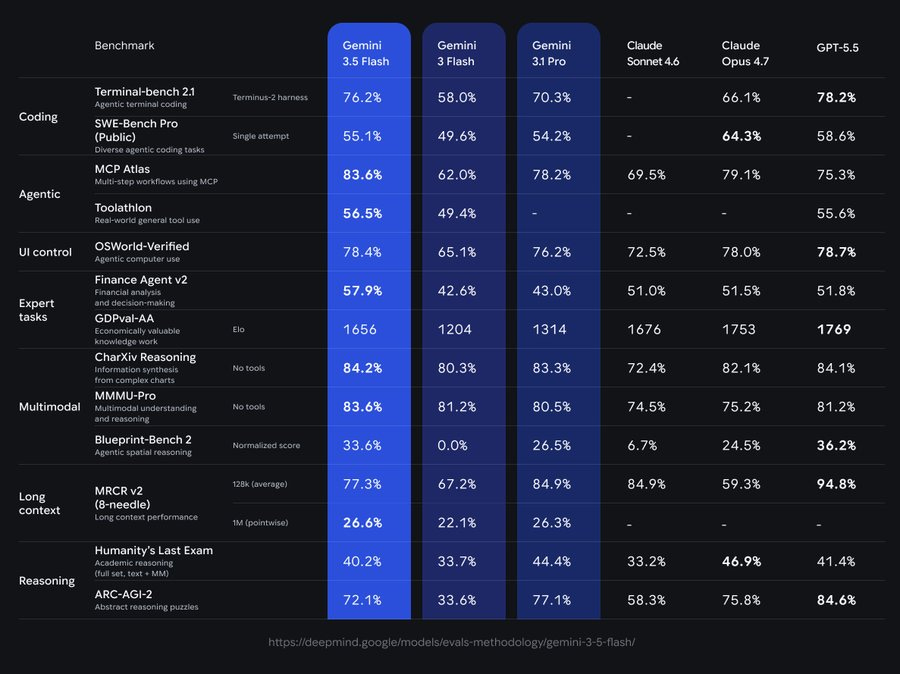
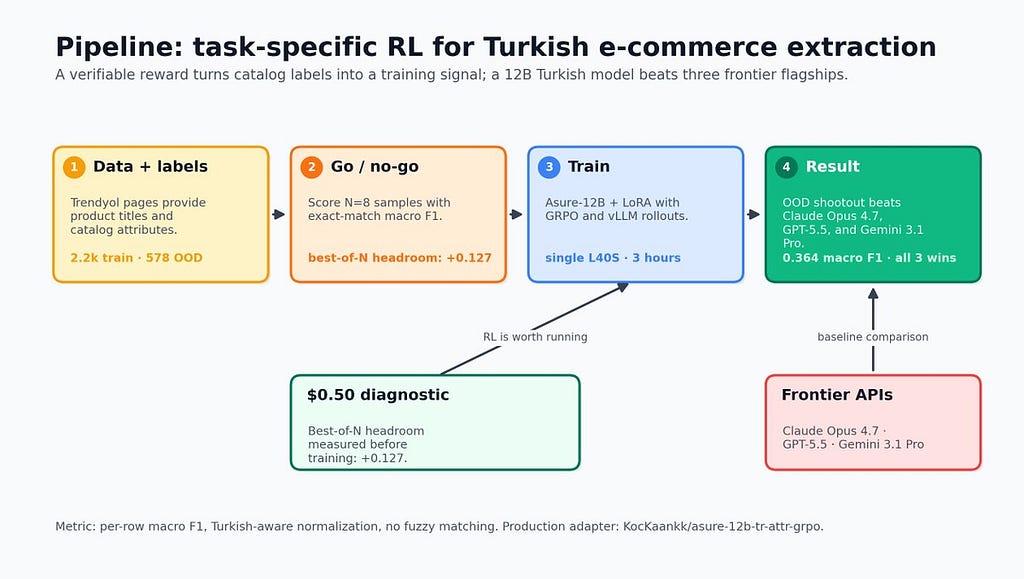
Claude's Pass Rate Under 4%, SaaS-Bench Tears Apart Computer-Use's 'Fully Automated Office' Fantasy
A new benchmark called SaaS-Bench has revealed that current AI agents struggle significantly with real-world, long-horizon tasks, with top models like Claude Opus 4.7 achieving less than 4% success rate on fully completing tasks. The benchmark uses actual SaaS systems and data, exposing four key failure modes: inability to maintain performance over extended tasks, cascading errors from single mistakes, a lack of self-checking mechanisms, and inconsistent performance across multiple runs. These findings suggest that the current paradigm for AI agents is insufficient for true automation and that software interfaces may need to be redesigned for AI agents rather than expecting them to operate human-centric interfaces. AI
IMPACT Reveals significant limitations in current AI agents for real-world automation, suggesting a need for new paradigms and software redesigns for AI interaction.