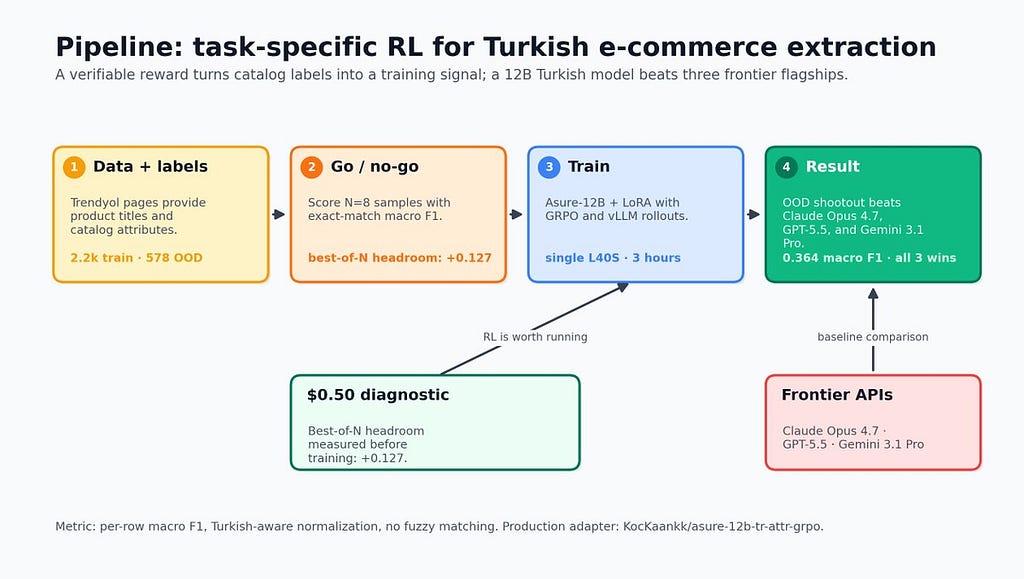
A researcher has demonstrated that a smaller, open-source Turkish language model can outperform frontier models like Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro on a specific e-commerce attribute extraction task. By fine-tuning the Trendyol-LLM-Asure-12B model with Reinforcement Learning from Human Feedback (RLHF) and using scraped product data for training, the researcher achieved statistically significant improvements in macro F1 scores. This approach offers a more cost-effective and accurate solution for specialized tasks compared to relying on general-purpose large language models. AI
IMPACT Demonstrates that specialized, smaller models can outperform frontier models on specific tasks, suggesting cost-effective alternatives for niche applications.
RANK_REASON The cluster describes a research experiment demonstrating a specific model's performance on a niche task, not a general model release or major industry event. [lever_c_demoted from research: ic=1 ai=1.0]
- Claude Opus 4.7
- Gemini 3.1 Pro
- GPT-5.5
- KocKaankk/asure-12b-tr-attr-grpo
- KocKaankk/tr-rl-eval-artifacts
- Trendyol/Trendyol-LLM-Asure-12B
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →