Introducing the Anyscale Agent Skill for LLM Post
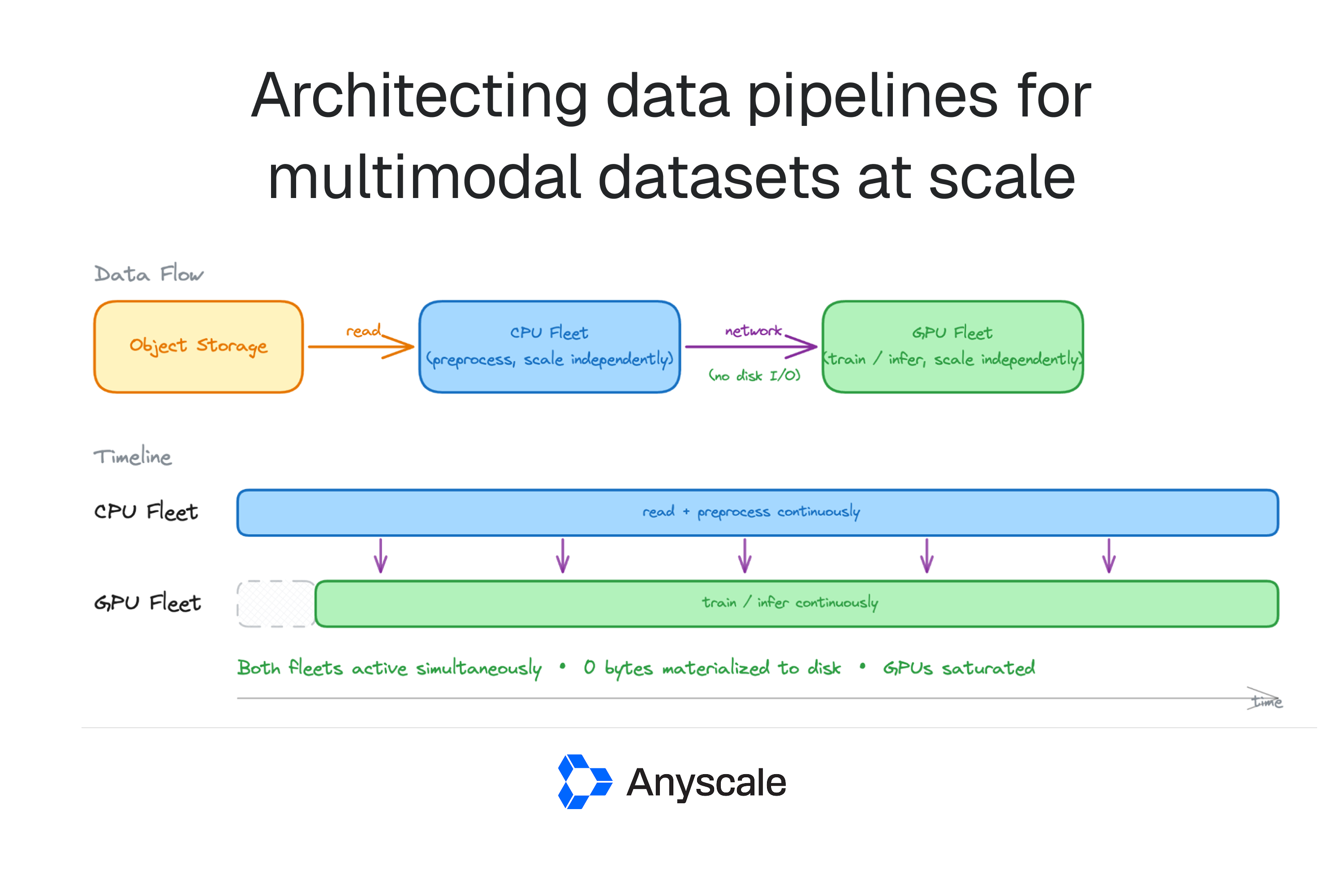
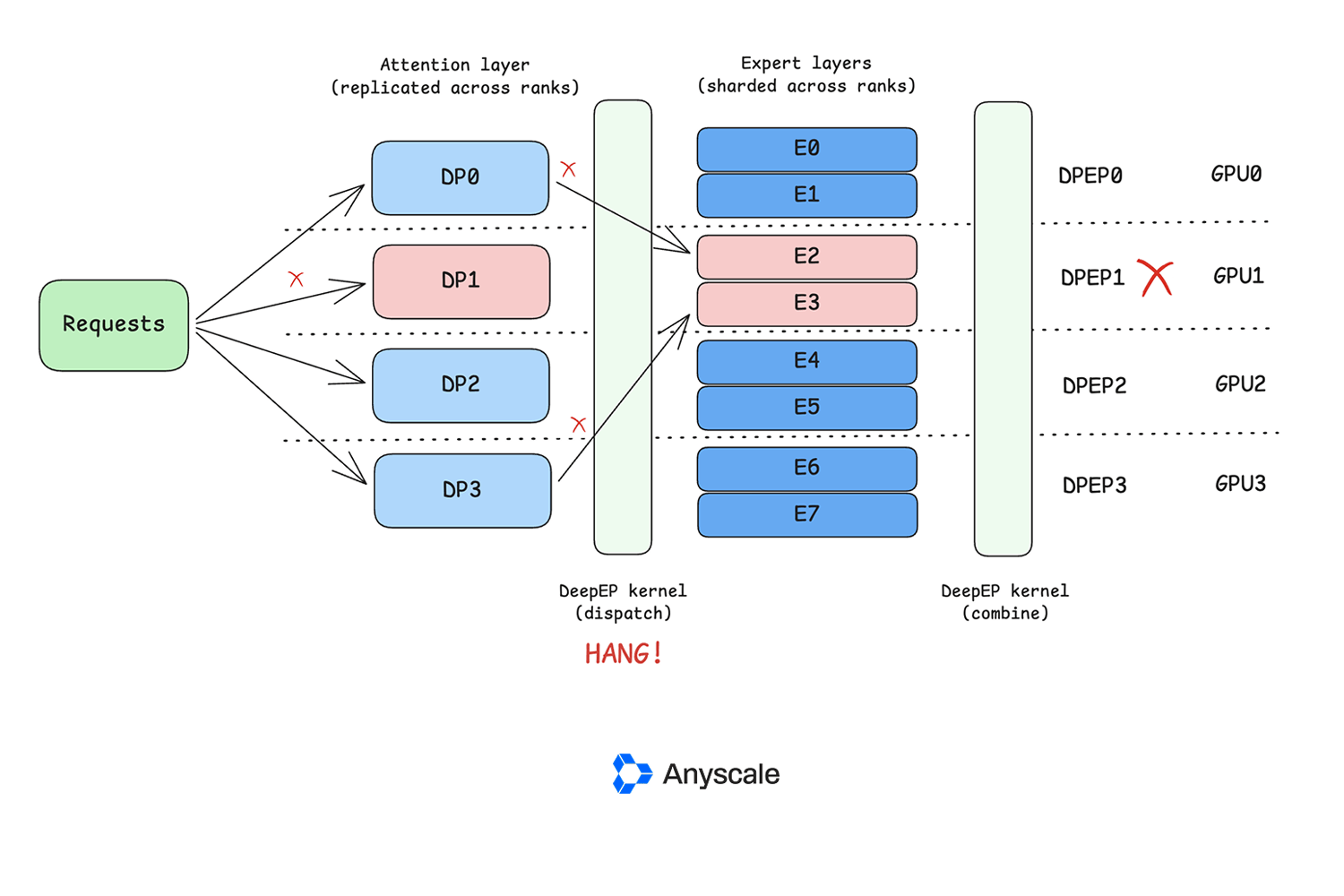
Anyscale has introduced a new Anyscale Agent Skill designed to simplify and automate the process of generating LLM post-training runs. This skill assists users in selecting the most appropriate post-training method, such as SFT, CPT, DPO, or RLVR, based on their model, dataset, and objectives. It then generates configuration files for popular frameworks like LLaMA-Factory and Ray Train, preparing them for deployment on Anyscale Jobs. AI

IMPACT Simplifies the complex process of LLM post-training, potentially accelerating adoption of advanced alignment and optimization techniques.