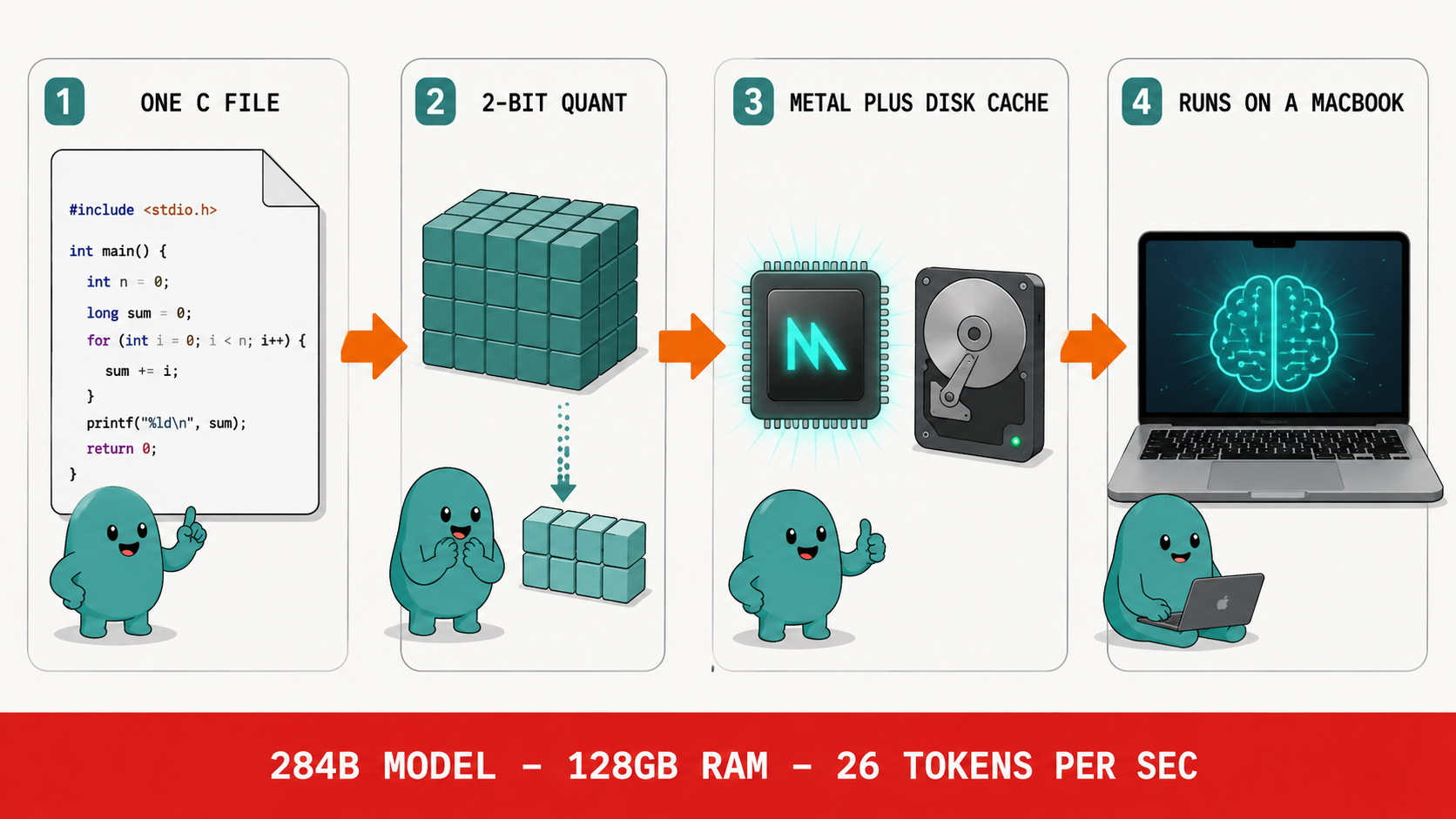
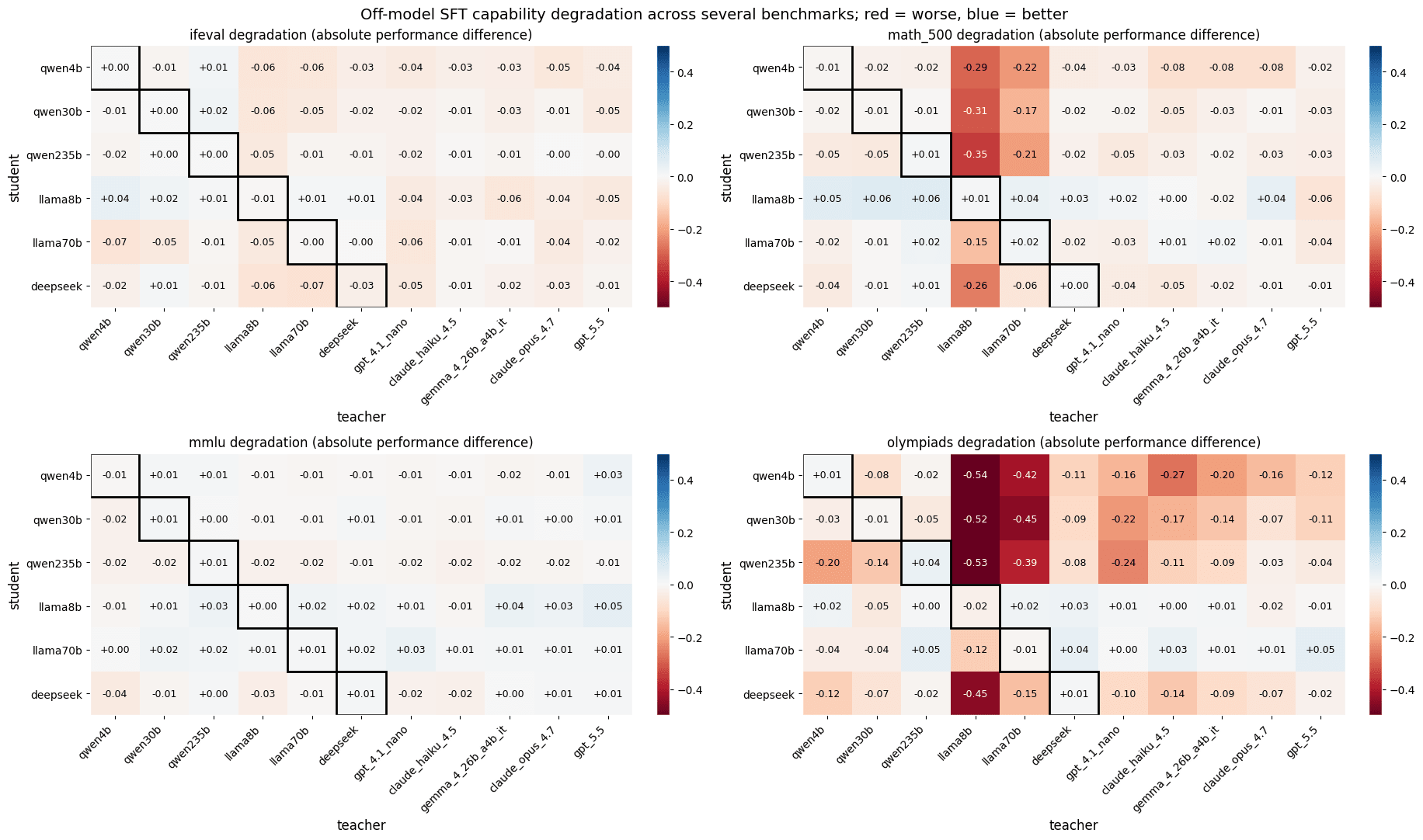
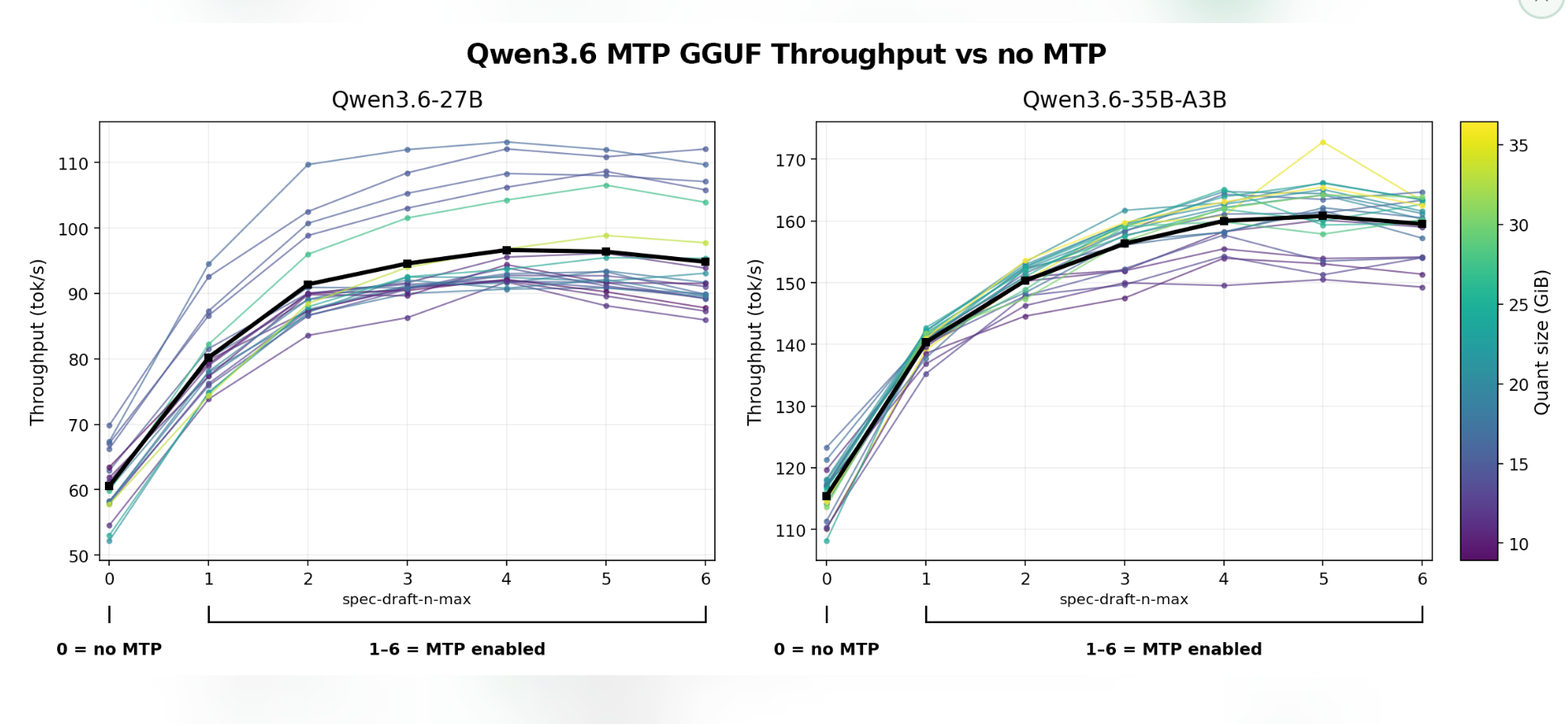
Krypton Evening News | Musk's SpaceX Launches Largest IPO Plan in History; First Comprehensive Driver Service Map Launched Nationwide; General Administration of Customs Releases Several Measures to Support the Construction of the Guangdong-Hong Kong-Macao Greater Bay Area in Guangdong
Alibaba's flagship Qwen3.7-Max model has achieved the top spot among Chinese large language models and ranks fifth globally, demonstrating performance comparable to leading models like GPT and Claude. This advancement is part of Alibaba's broader strategy to integrate AI into its e-commerce platforms for user acquisition and engagement. Meanwhile, AMD has begun mass production of its next-generation EPYC processors using TSMC's 2nm process, marking a significant step in high-performance computing. AI
IMPACT Sets a new benchmark for Chinese LLMs, potentially driving further competition and development in the domestic AI sector.