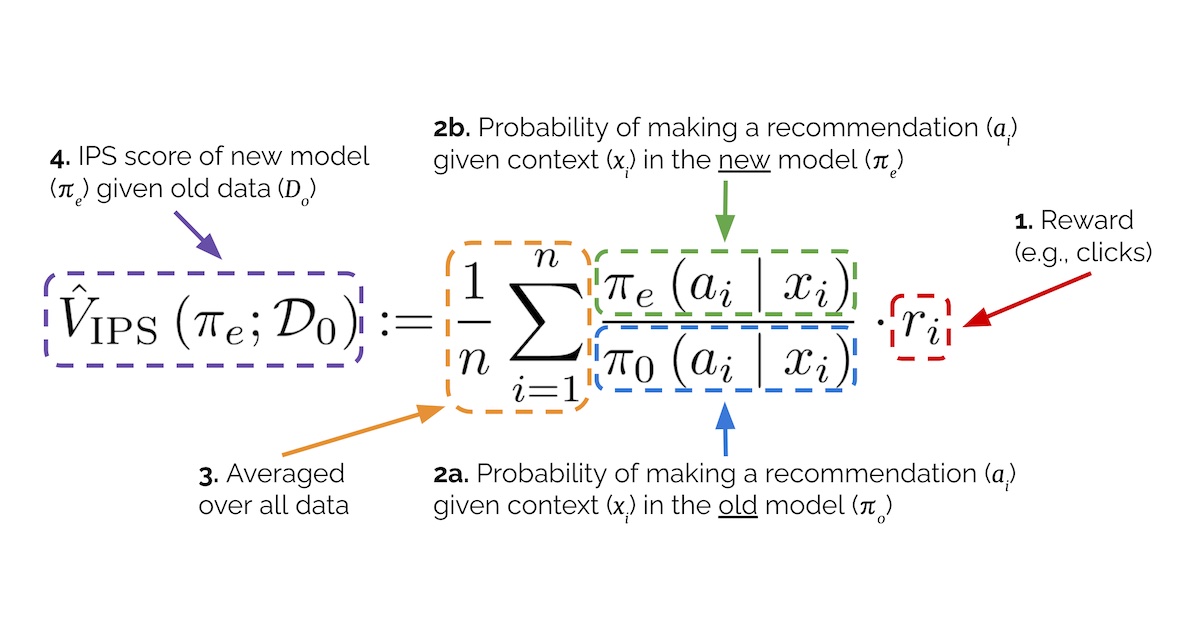
The Annotated Diffusion Model
Apple's research paper explores the mechanisms behind compositional generalization in conditional diffusion models, particularly focusing on how these models handle generating images with more objects than trained on. The study identifies 'local conditional scores' as a key factor enabling this ability, demonstrating that models succeeding at length generalization exhibit these scores, while those that fail do not. The research also proposes a method to enforce these local scores, which successfully enabled length generalization in a previously underperforming model. AI

IMPACT Research into diffusion model generalization could lead to more robust and controllable image generation systems.
- Niedoba et al.
- Johnson et al.
- Bradley et al.
- Phil Sidney Ostheimer
- Apple
- Kamb & Ganguli
- CLEVR
- SDXL
- Arwen Bradley
- Hugging Face
- LoRA
- InstructPix2Pix
- Diffusion language models
- Stable Diffusion
- Intel CPUs
- Conditional diffusion models
- Length generalization
- SAEmnesia
- Supervised Sparse Autoencoders
- Local conditional scores
- Diffusion Models