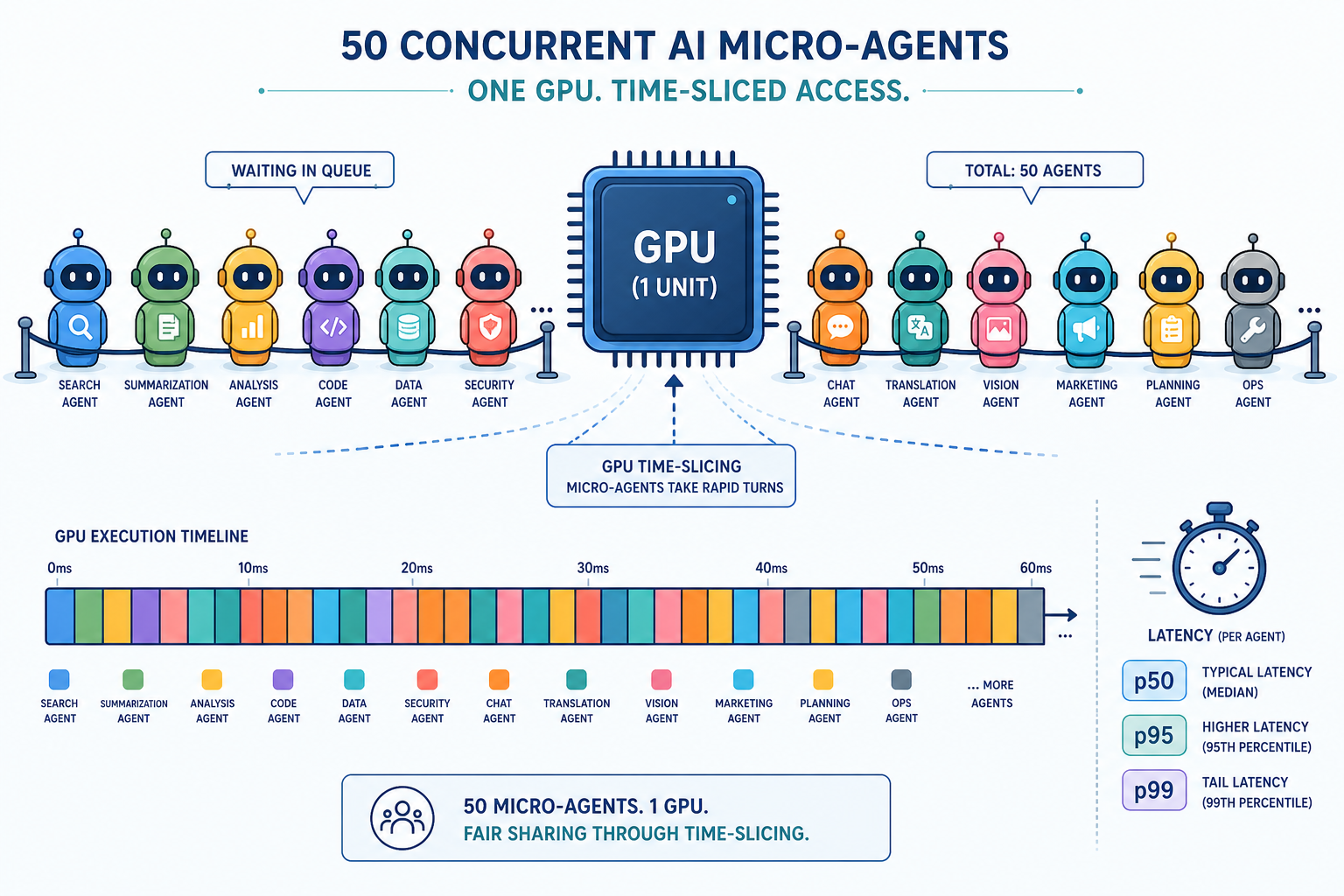
一位开发者发现标准的 LLM 服务框架效率低下,浪费了高达 98% 的 GPU 资源。为解决此问题,他们创建了一个自定义 C++ 后端。此自定义解决方案旨在优化 GPU 利用率,并降低运行大型语言模型相关的显著云成本。 AI
影响 优化 LLM 推理可以显著降低运营成本,并提高大规模部署 AI 代理的可行性。
排序理由 开发者构建了一个自定义工具来解决特定的技术问题。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
一位开发者发现标准的 LLM 服务框架效率低下,浪费了高达 98% 的 GPU 资源。为解决此问题,他们创建了一个自定义 C++ 后端。此自定义解决方案旨在优化 GPU 利用率,并降低运行大型语言模型相关的显著云成本。 AI
影响 优化 LLM 推理可以显著降低运营成本,并提高大规模部署 AI 代理的可行性。
排序理由 开发者构建了一个自定义工具来解决特定的技术问题。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
<div class="medium-feed-item"><p class="medium-feed-image"><a href="https://medium.com/@anbdwnroop.banerjee/i-built-a-custom-c-backend-because-standard-llm-serving-was-wasting-98-of-my-gpu-8f59db77c33a?source=rss------mlops-5"><img src="https://cdn-images-1.medium.com/max/1536/1*…