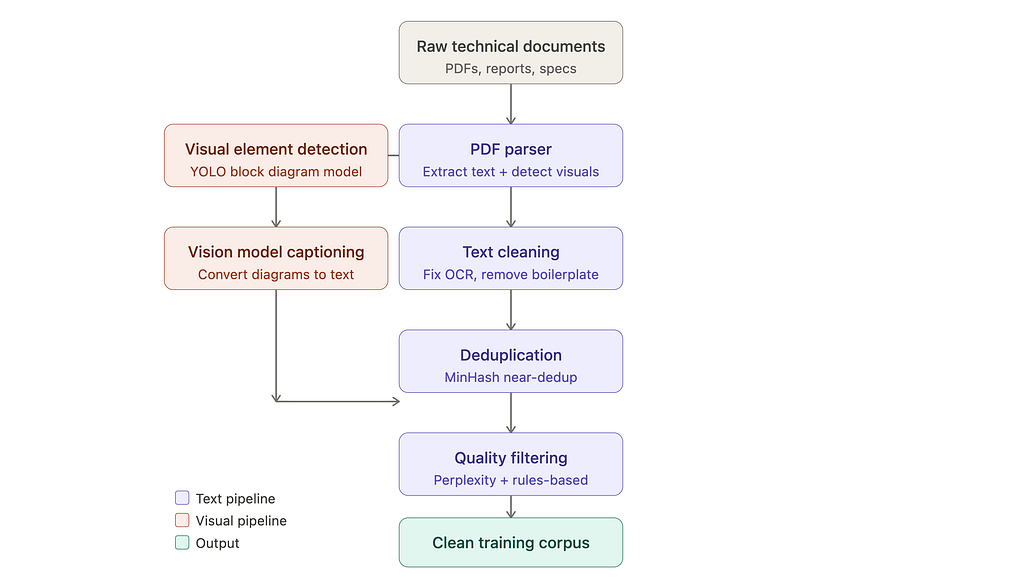
在技术文档上训练AI模型通常会忽略图表等关键视觉信息,导致理解不完整。标准的文本提取方法会丢弃这些元素,导致模型训练的数据存在重大的意义缺失。为解决此问题,采用了一种使用YOLO的计算机视觉方法来检测、分类和提取这些视觉组件,从而能够将它们与文本数据集成,实现更全面的文档理解。 AI
影响 通过捕获视觉数据来改进AI模型训练,从而更好地理解复杂的技术文档。
排序理由 文章讨论了一种通过整合文档中的视觉元素来改进AI模型训练的技术方法,这是一个面向研究的主题。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →