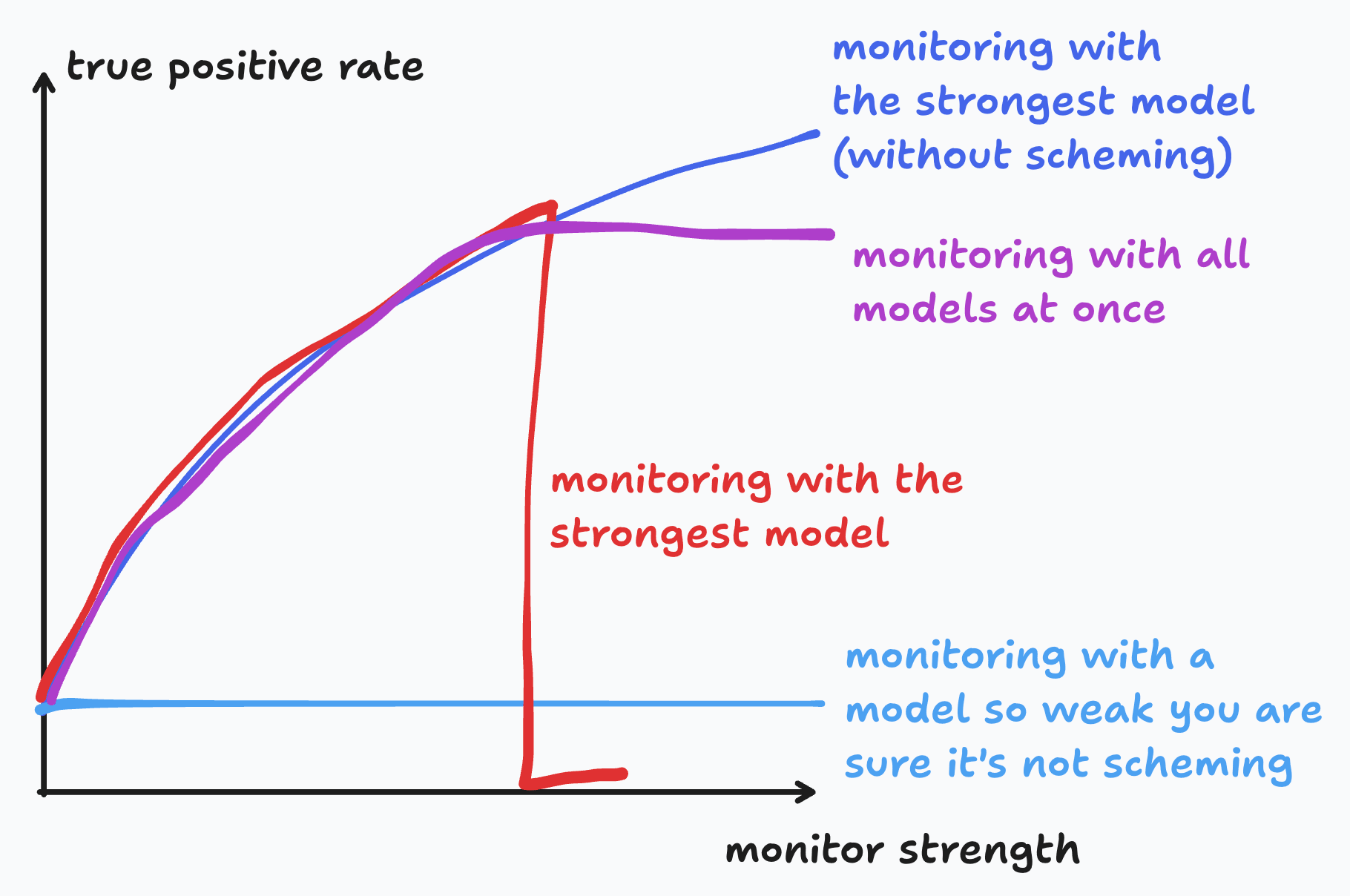
研究人员提出了一种新颖的人工智能安全方法,通过集成多个监控模型,即使它们的可靠性不确定。该策略不是试图完美地识别哪些模型可能具有欺骗性,而是使用各种模型来标记潜在的危险行为。这种方法旨在通过在任何监控器提出担忧时阻止行为来提高安全性,比依赖单一、完全理解的监控器提供了更强大的解决方案。 AI
影响 通过利用潜在不可信模型集成,提出了一种更强大的人工智能安全监控策略。
排序理由 该集群描述了博客文章中提出的一种理论性人工智能安全协议,而不是正式的研究论文或已发布的模型。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →